The Google File System, Ghemawat et al., SOSP 2003
The motivation for the GFS arised because the traditional filesystems didn't fit the bill for Google's use cases: Firstly, failures are continual (i.e., always happening) since Google has thousands of machines. Secondly, multi-GB files are common in Google due to mapreduce jobs. (Though, the paper does not mention mapreduce at all, the mapreduce paper appeared the next year in 2004.) And finally, again due to mapreduce, in Google's use cases file access is read/append mostly, random writes are very rare. (For mapreduce jobs, it was more important to have a high sustained bandwidth than low latency atomic appends.)
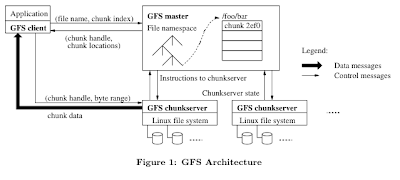
The GFS architecture is very simple (to the credit of the designers). Clients talk to a single master to get a handle on the chunk to read/write, and then using the handle clients pull/push the data to the chunkservers. Chunks are replicated over (by default) three chunkservers, one of which is designated as a primary replica by the master. So the master in fact provides three handles to the client for a requested chunk. The client can read from any of the three replicas, for example, it may choose the closest replica to read from. The client has to write to all three replicas, and the designated primary coordinates the 2-phase-commit of the write process on behalf of the client. (In sum, the write quorum is 3 out of 3, and the read quorum is 1 out of 3.)
While single master keeps things very simply, there can be some disadvantages to this decision. The single master can be a traffic bottleneck, but GFS prevents this by not involving the master in actual read/write, the master just provides the handle and gets out of the way. Leasing handles to clients also helps reduce traffic to the master further. The single master is also a single point of failure and availability could suffer, but GFS prevents this by using Chubby (which was actually again not mentioned in the paper, and appeared later in 2007).
As I mentioned above, the primary replica is used for coordinating write to the other two replicas. The client first pushes the data to all replicas, and then contact the primary with the write request. The primary forwards the write requests to replicas, and wait for the acknowledgements from the replicas. The primary then contacts the client about success or failure of the write.
I was concerned at this point about why a replica is being overloaded as being a primary and to coordinate a commit on behalf of the client. This only makes the replicas complicated, which could otherwise just have been hard disks basically. Why can't the client do this instead? The answer is because a chunk may be getting accessed my multiple clients simultaneously, and if the clients coordinate the writes the order may be very different in each replica; the replicas diverge. On the other hand, by using a primary replica these simultaneous accesses are effectively serialized with respect to the order the primary receives these requests, and the same order is dictated to all the replicas. So, the best place to do this is at the primary replica.
Another concern about the write process is that it would have large overheads for writing small files because of all the coordination the primary has to do. (Yes, GFS is designed for batch read/writes of large files.) I posited that an optimistic write approach could help alleviate this problem. Instead of doing a guaranteed write to all 3 replicas, the client may be given say 5 handles, and does an optimistic write (without any coordination, no primary, no 2 phase locking) to all 5 replicas at once. The assumption here is that at least 3 out of 5 of these replicas will be written. Then the read quorum should be chosen to be 3 for the small files (instead of the original 1 in GFS). By reading 3 out of 5 replicas, the client is guaranteed to see the most up-to-date version of the file.
The GFS architecture is very simple (to the credit of the designers). Clients talk to a single master to get a handle on the chunk to read/write, and then using the handle clients pull/push the data to the chunkservers. Chunks are replicated over (by default) three chunkservers, one of which is designated as a primary replica by the master. So the master in fact provides three handles to the client for a requested chunk. The client can read from any of the three replicas, for example, it may choose the closest replica to read from. The client has to write to all three replicas, and the designated primary coordinates the 2-phase-commit of the write process on behalf of the client. (In sum, the write quorum is 3 out of 3, and the read quorum is 1 out of 3.)
While single master keeps things very simply, there can be some disadvantages to this decision. The single master can be a traffic bottleneck, but GFS prevents this by not involving the master in actual read/write, the master just provides the handle and gets out of the way. Leasing handles to clients also helps reduce traffic to the master further. The single master is also a single point of failure and availability could suffer, but GFS prevents this by using Chubby (which was actually again not mentioned in the paper, and appeared later in 2007).
As I mentioned above, the primary replica is used for coordinating write to the other two replicas. The client first pushes the data to all replicas, and then contact the primary with the write request. The primary forwards the write requests to replicas, and wait for the acknowledgements from the replicas. The primary then contacts the client about success or failure of the write.
I was concerned at this point about why a replica is being overloaded as being a primary and to coordinate a commit on behalf of the client. This only makes the replicas complicated, which could otherwise just have been hard disks basically. Why can't the client do this instead? The answer is because a chunk may be getting accessed my multiple clients simultaneously, and if the clients coordinate the writes the order may be very different in each replica; the replicas diverge. On the other hand, by using a primary replica these simultaneous accesses are effectively serialized with respect to the order the primary receives these requests, and the same order is dictated to all the replicas. So, the best place to do this is at the primary replica.
Another concern about the write process is that it would have large overheads for writing small files because of all the coordination the primary has to do. (Yes, GFS is designed for batch read/writes of large files.) I posited that an optimistic write approach could help alleviate this problem. Instead of doing a guaranteed write to all 3 replicas, the client may be given say 5 handles, and does an optimistic write (without any coordination, no primary, no 2 phase locking) to all 5 replicas at once. The assumption here is that at least 3 out of 5 of these replicas will be written. Then the read quorum should be chosen to be 3 for the small files (instead of the original 1 in GFS). By reading 3 out of 5 replicas, the client is guaranteed to see the most up-to-date version of the file.





Comments