Lifting the veil on Meta’s microservice architecture: Analyses of topology and request workflows
This paper appeared in USENIX ATC'23. It is about a survey of microservices in Meta (nee Facebook).
We had previously reviewed a microservices survey paper from Alibaba. Motivated maybe by the desire for differentiation, the Meta paper spends the first two sections justifying why we need yet another microservices survey paper. I didn't mind reading this paper at all, it is an easy read. The paper gives another design point/view from industry on microservices topologies, call graphs, and how they evolve over time. It argues that this information will help build more accurate microservices benchmarks and artificial microservice topology/workflow generators, and also help for future microservices research and development.
I did learn some interesting information and statistics about microservices use in Meta from the paper. But I didn't find any immediately applicable insights/takeaways to improve the quality and reliability of the services we build in the cloud.
The conference presentation video does an excellent job of explaining the paper. I highly recommend watching it. For my brief summary, continue reading.
Topological characteristics

Figure 1 illustrates Meta’s microservice architecture. It is similar to other large-scale microservice architectures, in that there are load balancers hitting frontend services, which in turn call other services. They say that, at Meta, business use case is a sufficient partitioning for define [micro]services. Endpoints in the figure and the rest of the paper just means API interfaces.
The main findings related to topology are summarized below.
Finding F1: Meta's microservice topology contains three types of software entities that communicate within and amongst one another: (1) Those that represent a single, well-scoped business use case. (2) Those that serve many different business cases, but which are deployed as a single service (often from a single binary); (3) Those that are ill-suited to the microservice architecture's expectations that business use case is a sufficient partitioning on which to base scheduling, scaling, and routing decisions and to provide observability.
What are those ill-fitting services, you say? These have Service IDs of the form inference_platform/ model_type_{random_number}. "Meta’s engineers informed us that these Service IDs are generated by a general-purpose platform for hosting per-tenant machine-learning models (called the Inference Platform). The platform serves a single business use case--i.e., serving ML models-- but many per-tenant use cases. Platform engineers chose to deploy each tenant's model under a separate Service ID so that each can be deployed and scaled independently per the tenant's requirements by the scheduler."
ML bros, screwing things for systems guys since 2018 :-) On the other end of the spectrum, databases and other platforms appear as a single service and provide their own scheduling and observability mechanisms. And, the paper points out that, both of these extreme types of usage masks the true complexity of the services and skews service- and endpoint-based analyses of microservice topologies. This is an important point, and the paper does a good job of separating these ill-fitting services from others through out the evaluation section.

Finding F2: The topology is very complex, containing over 12 million service instances and over 180,000 communication edges between services. Individual services are mostly simple, exposing just a few endpoints, but some are very complex, exposing 1000s or more endpoints. The overall topology of connected services does not exhibit a power-law relationship typical of many large-scale networks. However, the number of endpoints services expose does show a power-law relationship.


Finding F3: The topology has scaled rapidly, doubling in number of instances over the past 22 months. The rate of increase is driven by an increase in number of services (i.e., new functionality) rather than increased replication of existing ones (i.e., additional instances). The topology sees daily fluctuations due to service creations and deprecations. The rate of increase of instances is due to new business use cases (i.e., new microservices) rather than increased scale: check the blue line in Figure 7.


Request-workflow characteristics
This section analyzes service-level properties of individual request workflows using traces collected by three different profiles.
- Ads: This profile represents a traditional CRUD web application focusing on managing customers’ advertisements, such as getting all advertisements belonging to a customer or updating ad campaign parameters.
- Fetch: This profile represents deferred (asynchronous) work triggered by opening the notifications tab in Meta’s client applications. Examples of work include updating the total tab badge count or retrieving the set of notifications shown on the first page of the tab.
- RaaS (Ranking-as-a-Service): This profile represents ranking of items, such as posts in a user’s feed.

Ok, back to the findings.
Finding F4: Trace sizes vary depending on workflows' high-level behaviors, but most are small (containing only a few service blocks). Traces are generally wide (services call many other services), and shallow in depth (length of caller/callee branches).


Finding F5: Root Ingress IDs do not predict trace properties. At the level of parent/child relationships, parents’ Ingress IDs are predictive of the set of children Ingress IDs the parent will call in at least 50% of executions. But, it is not very predictive of parents’ total number of RPC calls or concurrency among RPC calls. Adding children sets’ Ingress IDs to parent Ingress IDs more accurately predicts concurrency of RPC calls.
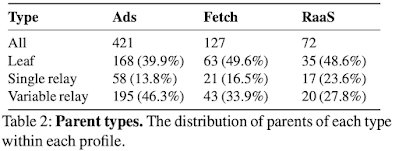


Finding F6: Many call paths in the traces are prematurely terminated due to rate limiting, dropped records, or non-instrumented services like databases. Few of these call paths can be reconstructed (those known to terminate at databases) while the majority are unrecoverable. Deeper call paths are disproportionately terminated.

What intrigued me was the solitary mention of memcache in this paper, which is peculiar given its prominence at Meta. In contrast, the Alibaba trace paper highlighted memcache's significance, revealing that in call graphs with over 40 microservices, approximately 50% of the microservices were Memcacheds (MCs).



Comments