Model Checking Guided Testing for Distributed Systems
This paper appeared in Eurosys 2023. It shows how to generate test-cases from a TLA+ model of a distributed protocol and apply it to the Java implementation to check for bugs in the implementation. They applied the technique to Raft, XRaft, and Zab protocols, and presented the bugs they find.
Background on the problem
Bridging the gap between model (i.e., abstract protocol) to the implementation (i.e., concrete code) is an important problem.
TLA+ gives validates the correctness of your abstract/model protocol, but does not say anything about whether your implementation of the protocol is correct. This is still very useful as Lamport likes to argue: if you didn't get the abstract design right, it doesn't matter if your implementation is true to the abstract, you will still have a flawed implementation. While having a TLA+ model checked abstract does not guarantee that your implementation of the abstract is correct, it helps you avoid the big/intricate protocol level problems and also provides a good reference for testing your implementation against by using other means.
Well, this is where we have been seeing a flurry of work in recent years.
Jesse Jiryu Davis and his coauthors from MongoDB had a great paper on their attempt to bridge this gap at VLDB 2020. They did try both approaches: model-based test case generation (MBTCG) that this Eurosy'23 paper uses, as well as the dual approach of going from implementation traces and using model to validate it, called model-based trace checking (MBTC).
The VLDB'20 paper was a great capture of the state of things in 2020. It nicely explained the challenges they faced (I should write a post on reviewing this). The paper talked about not only what worked, but also what didn't work. They found that "MBTC in a system of the MongoDB Server's scale will require significant effort for every specification. No initial infrastructure investment can make the marginal cost of trace-checking additional specifications cheap."
For the MBTCG side, which is the focus of the Eurosy'23 paper as well, the VLDB'20 paper says:
"MBTCG succeeded because the specification was deliberately written with a close correspondence to the implementation, via direct transcription. The implementation under test was a self-contained function with defined inputs and output, of approximately one thousand lines of code. By design of the OT algorithm, the order of clients exchanging operations they performed locally does not change the transformed version of these operations or the resulting array. As a result of this symmetry, model-checking the specification is feasible, and the implementation can be completely tested by a constrained set of tests that can be generated, compiled, and run fairly quickly."
The Eurosys'23 paper re-affirms the conclusion from the VLDB'20 work, saying that the model needs to be close to the implementation for the model-based test case generation to work. They made modifications to existing model to make them align when needed. More on this later. The Eurosys'23 paper also improves on the VLDB'20 paper by adding support for common non-deterministic features in distributed systems, e.g., message communication and external faults.
On the MBTC side, there is work in progress as well. It looks like Markus and his collaborators made some good progress and getting results from the code conformance checking side. This is again building on Ron Pressler's idea and prototype that the VLDB'20 paper also used. The sequence of states generated from the implementation is fed to the TLA+ model by using TLC.
To wrap up this background review, I would like to mention an opportunity in this space. In April, TLA+ Foundation has been established under Linux Foundation. The board will be sending out a call for proposals on TLA+ tools/development. I expect that both test-case generation and conformance checking would be directions for funding work on.
The Mocket Approach
Mocket is the name of the framework the authors of this Eurosys'23 paper developed in order to test distributed system implementations with respect to TLA+ models. Mocket applies for Java implemetations and the code is available here. Mocket is implemented in Java and Python, and consists of around 5K lines of code (LOC). The annotations for mapping variables and actions are implemented based on java.lang.annotation package. The runtime instrumentation is performed based on ASM library. The test case generation is implemented based on Python’s networkx package.

Here is an overview of Mocket.
First, the TLA+ model checker (TLC) is used for generating a state space graph in a GraphViz DOT file after checking a TLA+ specification. In the state space graph, each edge denotes an action, and each node denotes a state. (I suppose this could get quite big. For a small ping like protocol, Figure 2 shows the generated state space graph.)

They traverse the state space graph to generate executable test cases in a real-world distributed system. A test case is a path in the state space graph, which starts from the initial state. (By using a more sophisticated replaying/recording system it may be possible to relax this "start from initial state" constraint to start from some intermediate state of interest.) To test a real-world distributed system within a limited time, they apply edge coverage guided graph traversal and partial order reduction optimizations to generate representative test cases.
They do manual annotation followed by some automated instrumentation of the Java code. For example, as Figure 4 shows, this is how you annotate to map the TLA+ Raft model variable nodeState and the action BecomeLeader to the corresponding Raft-java implementation.

For each TLA+ variable that is mapped to a class variable/method variable in the target system, Mocket then automatically adds a shadow field/variable in the implementation. Further, whenever a variable in the implementation is initialized or reassigned, Mocket assigns the same value to its corresponding shadow field/variable. For example, in Figure 4b, Mocket adds shadow field Mocket$state (Line 4) for the annotated class field state (Line 3) in the implementation, and when state is initialized as STATE_FOLLOWER (Line3) and reassigned to STATE_LEADER (Line 10), Mocket$state is set as the same value (Line 5 and 11).
To run tests, it seems like the concrete implementation is run, and when it is blocked at an interjection point, the abstract is run to select among the options that would match the abstract test case progression.

Evaluation
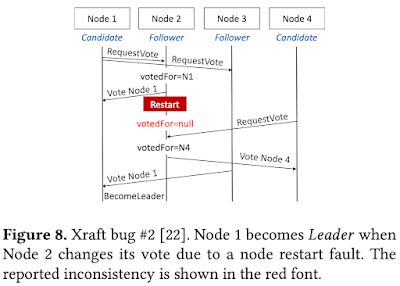
They tested with ZooKeeper and Raft, and Xraft. All the three unknown/new bugs found were found in XRaft. This is not surprising as Xraft is not production code, it is used as the code example in a published book that introduces Raft. Since all models are closely related the evaluation fails to demonstrate that Mocket is generalizable to other Java-based systems. With Paxos, you have a very isolated component, sort of a root component that other system components are just customers of the logs. For a different component with large surface area of interaction with other components, driving the implementation would be very challenging as you would need to interject/control many other components to wait/block on desired input for the test trace to be realized.


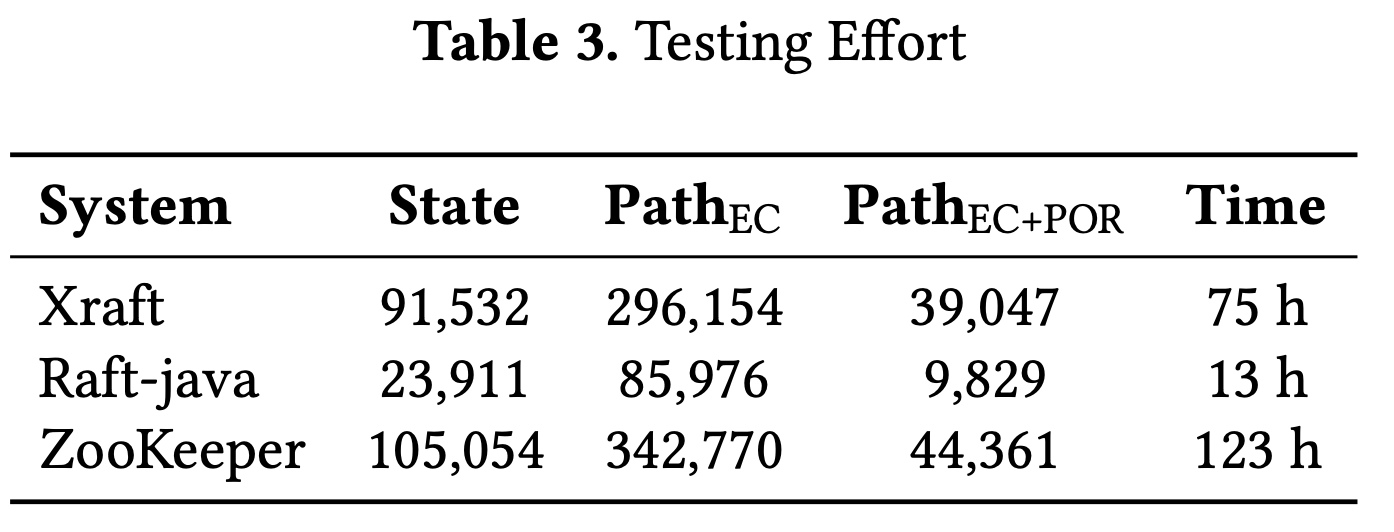
On average, a ZooKeeper test case takes about 10 seconds. Xraft and Raft-java take 7 seconds and 5 seconds to execute a test. Table 3 shows the length of overall testing effort for all traces of the model.
Mocket can miss some implementation bugs. Here is an example category they mention. This seems like a severe limitation of test-case generation approach to me.
"If some concurrency in the system implementation is not properly modelled in the TLA+ specification, we can miss related implementation bugs. Assume that action a_i must happen before a_j in the TLA+ specification, while a_i and a_j can be concurrently scheduled in the system implementation. In such case, Mocket cannot test the schedule a_j happened before a_i, and hence misses related implementation bugs hidden in this schedule."
Discussion
TLA+ helped here in two ways. The first is to validate that the abstract model is correct. The second is the outputing of the GraphViz DOT file that Mocket take as input for test case generation. Any other modeling that would satisfy these two would also fork for Mocket.
For the test-case generation approach, both the VLDB'20 and this paper observed that the model needs to be too close to the implementation. I think the reason for this is because of the false-positives that would arise due to the nondeterministism at the abstract model. I wished the paper stated this explicitly as the explanation, but I haven't found a mention of this in the paper.
Here is how this argument goes: Any execution of the implementation (with proper mapping) should be an acceptable execution of the abstract. But there can be executions of the abstract that are not acceptable executions of the implementation. This is basic definition of Liskov refinement. This is not a bad thing, you like your abstract to be, well, abstract, and allow multiple implementations. Lamport would not like the idea of the abstract shadowing the implementation closely. Abstract is meant to allow more nondeterminism. The solution then is to write another intermediate model closer to the implementation. The correct way to do this is to write the intermediate model as a verified refinement of the abstract, lest you introduce some subtle bugs. As the model size grows, it is possible to introduce these subtle bugs, because you may not write sufficiently detailed correctness invariants and may not have introduced sufficient fault actions to stress the design. I had seen this in my models, and I am now a convert to this stepwise refinement of writing models.
When writing longer closer-to-concrete models, you get a lot of help from TLA+ as it makes it super convenient to check for refinement. I am going to write a post on this later, but if you are interested check this lecture and TLA+ models from Lamport on Paxos validated (and discovered in the first place) as stepwise refinement.
How much close would the TLA+ models need to be? How much modification was needed on the TLA+ models for the evaluation? I wanted to check on this, but the github repo does not have TLA+ files, it only includes the dot file output from TLC. (The authors are preparing for another submission on a related paper, and didn't want to release the TLA+ before that.)
Going to another topic for discussion, let's consider imposing control of a deterministic test case/schedule on the distributed (hence non-deterministic) implementation system. Jack Vanlightly observed:
"Generating deterministic tests for non-deterministic systems requires hooks into the system to pause nodes at the right time and override certain logic (using ASM in Mocket's case and Mocket framework code to handle the logic). It's applying simulation testing to a system that wasn't designed for that. It would be interesting to see this technique of generating deterministic test cases from TLA+ state spaces but applied using a system that has simulation test support already built-in."
The Turmoil approach of deterministic testing would be a way to address this for upcoming work.





Comments