Timestamp-based Algorithms for Concurrency Control in Distributed Database Systems
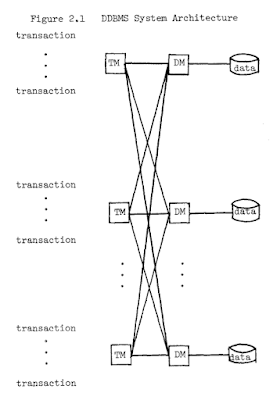
This paper by Bernstein and Goldman appeared in VLDB 1980. Yes, 1980, more than 40 years ago. This may be the oldest paper I wrote a summary for. The paper is written by a typewriter! I really didn't like reading 10+ pages in coarse grained typewritten font. I couldn't even search the pdf for keywords. Yet, the paper talked about distributed databases, and laid out a forward looking distributed database management system (DDBMS) architecture with distributed transaction managers (TMs) and data managers (DMs), which is very relevant and in use even today. I really loved the forward looking vision and clear thinking and presentation in the paper.
Timestamp order (TSO) based approach is synonymous with optimistic concurrency control (OCC). The essence of TSO is OCC, because we don't lock and we optimistically check whether we are still OK. There is a subtle difference between what is called basic TSO and OCC protocol. Basic TSO assigns timestamps to transaction on start, and checks reads as and when accesses are made. OCC takes the lazy route, and checks all of the accesses in batch at the end and assigns the timestamp to the transaction at this point. We will touch on this difference later in the post. (The paper refers to timestamp order as T/O algorithm. I shorten it as TSO here as I don't want to keep typing /, and also because TSO reminds me of General TSO's chicken... Mmm, yummy.)
Let's get to the basic TSO protocol and discuss variants and extension to OCC after that.
Basic TSO protocol
TSO protocol uses timestamps to determine the serializability order of transactions. It ensures that: If timestamp of transaction ti, i.e., ts_ti, is less than ts_tj, then the execution of both should be equivalent to the serialization of transaction ti followed by transaction tj.
This is how that is implemented in the basic TSO protocol.
Each transaction ti, is assigned a timestamp on start, ts_ti.
Every object x is tagged with the timestamp of the last transaction[s] that successfully read/write x. So, object x has two metadata associated with it: read_ts(x) and write_ts(x). To guarantee the above serializability property, it is crucial that these timestamps should be monotonically increasing. The update protocol checks and ensures this for each access.
If a transaction tries to access (read/write) an object from its future it is aborted. For example, if ti finds that it is reading x, which has write_ts(x)>ts_ti, then this would be a future read, and x aborts itself. It may later be retried with a new/higher ts, and hopefully it will succeed then.
Otherwise, the access to object x is granted and the corresponding read_ts(x)/write_ts(x) is updated to the maximum of its old value and this ts_ti. The transaction makes a copy of objects it reads, to ensure repeatable reads.
This is not a one-shot transaction, the transactions may be reading writing multiple objects one after the other. For example, ti may read x, write x, then read y, write y. As long as the above rule of no access granted to future objects is followed, and the object read_ts and write_ts updated accordingly, the resulting execution is guaranteed to satisfy serializability.
It is a simple rule, and it works (well, there are some downsides as we discuss below). Its performance is not too shabby either, as we discussed before when we reviewed "An Evaluation of Distributed Concurrency Control (VLDB'17)."
TSO avoids deadlock because transactions don't wait on each other. The older transaction that is trying to access an object with a higher timestamp (that is one accessed by a newer transaction) gets rejected and is aborted. This means that starvation is possible for some long transactions, even after some retries with higher timestamps.
Another drawback is that if one transaction/transaction-manager has a clock that is far ahead of others, it will keep using timestamps so high that this will essentially mean unavailability for other transactions. This is tricky to manage. Implementing TSO is simple but keeping it operational/available to the face of clock/timestamp shenanigans is not very easy. Do you instruct the storage nodes to reject requests that are too far ahead of their local clock? What if the storage node clock is off? Even with logical clocks similar problems are possible.
These two drawbacks are inherent to all timestamp based concurrency control protocols, not just basic TSO, and there is no easy fix.
Here I should mention that the version of basic TSO explained in Pavlo's database class (see 2018 and 2019 videos) is different than the version Bernstein paper presents. Pavlo's database class uses a centralized version of basic TSO, even though the version explained in the Bernstein paper is distributed. The basic TSO explained in the class used in-place updates, although Bernstein's paper talked about private workspace updates for writes and validation at the end like OCC. Finally, although the basic TSO version described in Pavlo's class is not crash-recoverable, Bernstein's paper talked about the use of 2 phase commit for crash-recovery (although it is not without problems).
In Bernstein's basic TSO, write operations create/update the value of x in ti's private workspace to the new value. and when ti issues its END operation, two-phase commit begins. For each x updated by ti, and for each stored copy xi of x, the TM issues a pre-commit(xi) to the DM that stores xi. The DM responds by copying the value of x from ti's private workspace to its durable workspace. After all precommits are processed, the TM issues dm-writes for them. DMs respond to this by copying the value of xi from their durable workspaces to the stored database. And the transaction is concluded. If a TM fails after issuing its first dm-write, the paper says the DMs conclude the commit process. For this, each DM that receives a precommit must be able to determine which other DMs are involved in the commit. On failure, the DMs that did not receive commit consult the other DMs and finish the commit. Yes, this is very hand wavy, and incorrect in the presence of failures and asynchrony. Viewstamped replication and Paxos was not available then.
The Optimistic Concurrency Control (OCC) protocol (Kung Robinson 1981) came a year after Bernstein's paper, and said that it pays to be lazy. It presented a slight twist on basic TSO. In contrast to the basic TSO protocol where a transaction gets its timestamp at the start, in OCC a transaction gets its timestamp assigned at the validation phase. Moreover, in OCC, all the read validation is also done as batch at the end, rather than as they happen in basic TSO. (Write validation happens at the end in both.)
In OCC, each transaction has a private workspace for doing its modifications. (Bernstein's basic TSO also had this, and I am surprised to see that the OCC paper did not cite the Bernstein paper which came a year earlier.) A transaction makes the updates at its local workspace, and then when all of the accesses to objects and modifications are done, it starts a validation phase, to check for conflicts of these reads/writes with the other transactions updating the database. So OCC has three phases:
- read phase (badly named, this is actually reads and local modifications)
- validation phase (this is where the timestamps are checked for serializability)
- write phase (this the installation of the local updates on the database)
The OCC paper considered a centralized database and did not need two phase commit for recoverability.
Other TSO protocols considered in the paper
The TSO paper considers three other methods, in addition to the basic TSO method, namely Thomas's write rule, multiversion TSO, and conservative TSO.
The paper separates the serializability problem into read-write and write-write synchronization subproblems. For rw synchronization, two operations conflict iff both operate on the same data item and one is a dm-read and the other is a dm-write. For ww synchronization, two operations conflict iff both operate on the same data item and both are dm-writes.
By choosing one of the three methods (Thomas's Write Rule does not qualify) for rw synchronization, and one of the four for the ww synchronization, the paper gives 12 variations on concurrency control. One of these variations is incorrect, because it uses multi-version TSO for rw synchronization and Thomas's write rule for the ww synchronization. Pretending the write happened, rather than actually putting it in place does not work with multi-version reads, and this invalidates this variation.
The paper does not provide any evaluation of these 11 concurrency control protocols, and leaves that for other work.
Thomas's write rule (TWR)
TWR helps optimize the basic TSO protocol by pretending that a write happened, and by not actually performing it.
If ts_ti < write-ts(x), rather than rejecting the dm-write (and restarting ti) TWR simply ignores the dm-write and allows ti to continue. Because ti's write would have been overwritten anyway, no harm done. But there are complications to TWR. What happens if there is a restore of database to a point in time? Or what about logs? The logs don't lie. You pretended it happened, but it didn't. And as mentioned above, TWR for ww-sync won't work for using multiversion TSO for rw-sync for the same reason.
Multiversion TSO
For rw synchronization, the basic TSO can be improved by storing multi-versions of the data item in time. Using multiversions, it is possible to achieve rw sync without rejecting any dm-reads because we have that version available for reading. However, dm-writes can still be rejected. Consider the dm-write in the figure below.

Conservative TSO
This is a technique for reducing restarts during TSO scheduling. When a scheduler receives an operation that might cause a future restart, the scheduler delays that operation until it is certain no future restarts are possible. This comes with a lot of assumptions (such as each Tm talk to all schedulers) and has implementation and scalability problems. The paper tries to address these by proposing remedies, such as using transaction classes.





Comments