TAOBench: An End-to-End Benchmark for Social Network Workloads
TAOBench is an opensource benchmarking framework that captures the social graph workload at Meta (who am I kidding, I'll call it Facebook). This paper (which will appear at VLDB'2022) studies the production workloads of Facebook's social graph datastore TAO, and distills them to a small set of representative features. The integrity of TAOBench's workloads are validated by testing them against their production counterparts. The paper also describes several use cases of TAOBench at Facebook. Finally, the paper uses TAOBench to evaluate five popular distributed database systems (Spanner, CockroachDB, Yugabyte, TiDB, PlanetScale).
The paper is a potpourri of many subquests. It feels a bit unfocused, but maybe I shouldn't complain because the paper is full to the brim, and provides three papers for the price of one.
TAO
TAO is a read-optimized geographically distributed in-memory data store that provides access to Facebook's social graph for diverse products and backend systems. TAO serves over ten billion reads and tens of millions of writes per second on a dataset of many petabytes. TAO provides access to objects (nodes) and associations (edges) in the social graph. Objects are uniquely identified by an id while associations are represented by a tuple: (id1, type, id2). TAO's API consists of point get, range, and count queries, operations to insert, update, and delete objects and associations, and failure-atomic write (multi-put) transactions.
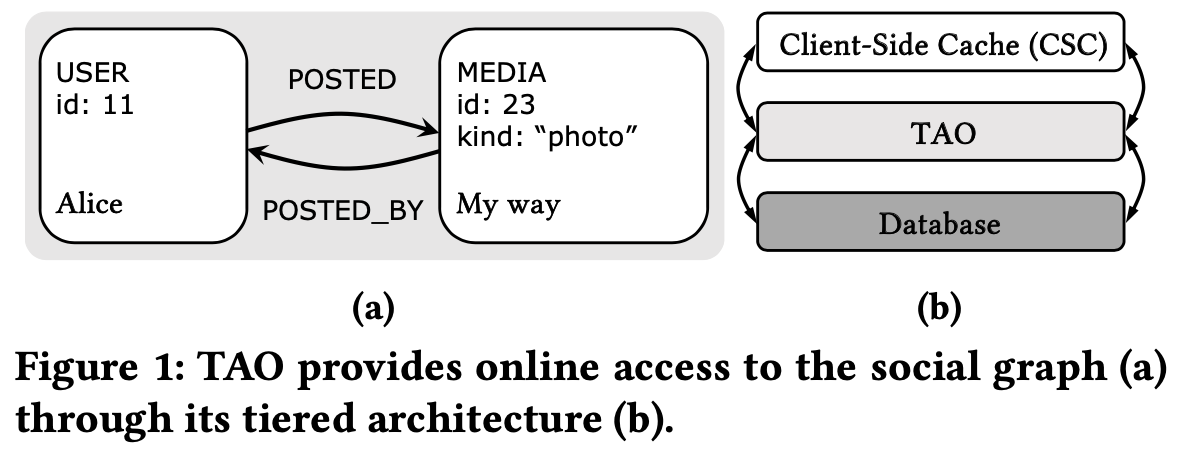
While TAO was initially designed to be eventually consistent, it has since added read-your-writes (RYW) consistency, atomic (per-key) preconditions on writes, one-shot write-only transactions with failure atomicity, and prototyped read-only transactions. TAO's write transactions are implemented with two-phase locking (2PL) and a two-phase commit protocol (2PC).
Earlier, I had covered the RAMP-TAO paper, which details how atomically-visible read transactions (where reads observe either all or none of a transaction's operations) can be layered on top of TAO. TAO is not a multiversion datastore, but the RAMP-TAO work morphed it to a faux-multiversion by using the Refill-Library metadata cache with recent versions to implement consistent read transactions.
Characterization of TAO's Production Workload
To characterize TAO's workload, the paper analyzed traces of requests collected over three days. The collected trace is comprised of 99.7% reads, 0.211% writes, and 0.0162% write transactions. Here, reads denote all types of queries on TAO (point get, range, count), writes denote all single-key operations that modify data (insert, update, delete), and write transactions denote requests using either the single-shard or cross-shard, failure-atomic API.
Operation skew

Figure 2 shows that there is significant variation between the key access distributions of the top 400K keys of reads, writes, and write transactions. The P90 access frequency is 3.3M requests per day for reads and 3.3K requests per day for both writes and write transactions.

Read and write (transaction) hotspots do not always align and may be expressed on different keys across operation types. While a post by a celebrity may be both viewed and liked often (right circle on Figure 3a), data items generated by internal applications (data migration and processing) may be read infrequently (left circle).

Key access distributions for reads vary between tiers. The client-side cache (CSC) serves 14.1% of reads, TAO serves 85.0%, and the database (DB) serves the remaining 0.872% of queries. Figure 4 shows how the read frequencies of the top 400K keys of each tier compare in the two other tiers.

Read and write (transaction) latency distributions are bimodal due to cache misses and cross-region requests. As Figure 5 shows, request latency between read and write operations differs significantly since all writes must go to the primary region database (on average, 13.4 ms for reads, 80.0 ms for writes, and 61.9 ms for write transactions). Note that the x-axis in Figure 5 is log-scale, like all Figures in Section 3.
This is a big point of confusion. The latencies are, on average, 13.4 ms for reads, 80.0 ms for writes, and 61.9 ms for write transactions. But the graphs, such as Figure 5, give these latencies in x-axis with microsecond units. There is a 3-order of magnitude difference between microsecond and milliseconds, but the bumps in latencies seem to almost line up within 1-order of magnitude, which leds one to suspect that the x-axes are just mislabeled. Footnote 4 seems to be written specifically to address this confusion:
Footnote 4: Note the x-axis of Figure 4d is in log scale, so the long tail of each distribution is not apparent in the graph. For example, the P50 latency is 1.76 ms for the CSC, 1.87 ms for TAO, and 13.7 ms for the DB.There is almost 1-order of magnitude difference between P50 and average latencies, because the long tails on these operations are brutal. Referring to average latencies on such a skewed distribution is very misleading.
Ok, another surprise?! How can write transactions have lower average latency than plain writes? The paper says the following, but I still don't get how this can happen. "Writes and write transactions have similar request latencies because transactional use cases are carefully vetted for performance, and most currently involve small write sets. All operation types exhibit long tail latencies due to client-side delays (e.g., network latency) and asynchronous tasks, which are off-peak, analytical jobs that involve more complex queries." Maybe the distribution tails across operation types (Figure 2) gives some clue. Write key access distribution has a heavy tail. And remember writes are 10 times more common than write-transactions, so this heavy tail may be taking its toll on average write performance. Write-transaction keys may have better colocation by design, and their tail is significantly shorter in Figure 2.
The bimodal latency distribution in Figure 5 is both good news and bad news. It means that caches help a lot in reducing latency. But we also lose predictability of the performance, and that can be important. Also caches make the system prone to metastable failures. Why don't Facebook solve this unpredictability problem? Maybe this is very hard to solve due to the brutally skewed social network workloads. Another big factor could be "cost". They have cache-based tiered architecture, because they have to be very cost conscious. Facebook does not make money off of the predictability of TAO, so they go with an unpredictable latency solution, which is much cheaper.
Write transactions


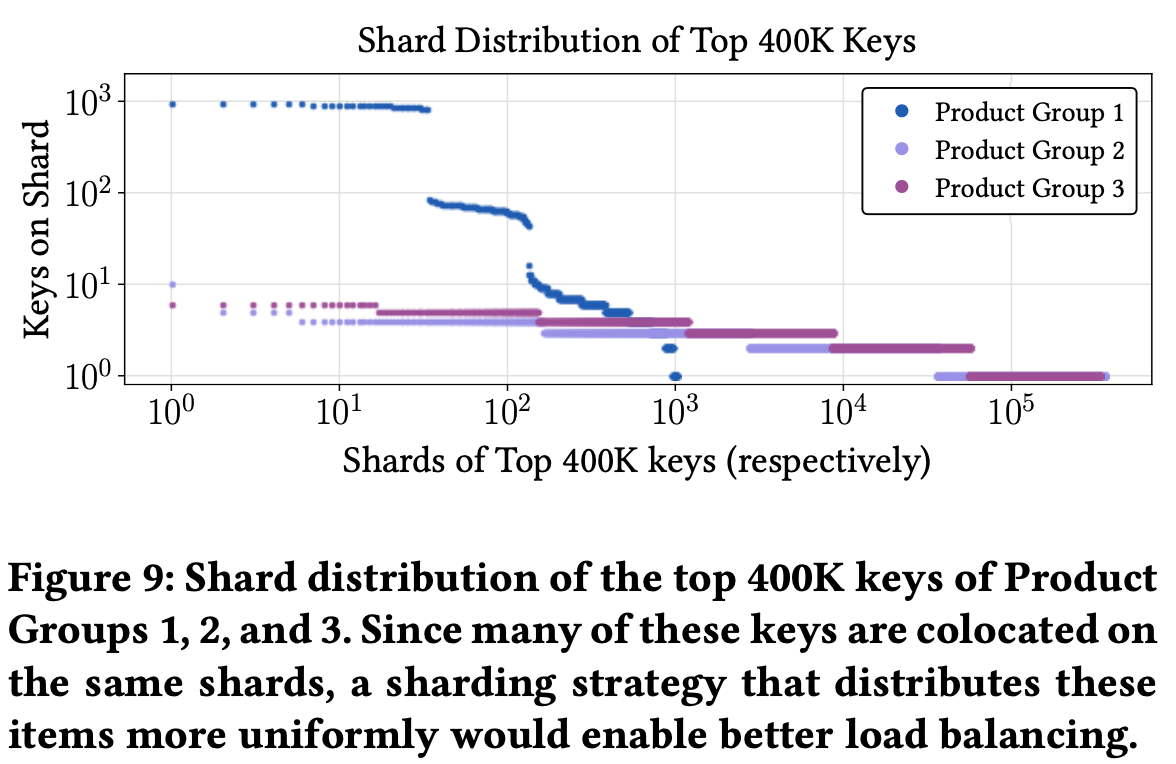
Hot keys in write transactions tend to be colocated on the same shards. More than 93.9% of hot data items are colocated with at least one other frequently requested item for Product Group 1, 10.0% for Product Group 2, and 17.0% for Product Group 3 (Figure 9). While popular data items are often clustered on a small number of shards, we find that they are rarely part of the same transactions. Hot keys may have been intentionally colocated by application developers to improve the efficiency of batched requests. These results demonstrate a tradeoff between load balancing and the performance of a subset of queries.
There are three main transaction types: TX1 are small transactions
(<10 operations) on hot keys, TX2 involve large transactions on both
hot and cold keys, and TX3 are large transactions that access keys of
similar frequency. Product Group 1 contains TX1 and TX2. Product Group 2
executes TX1 and TX3 transactions. Product Group 3 contains TX2 and
TX3.
Workload Parameters
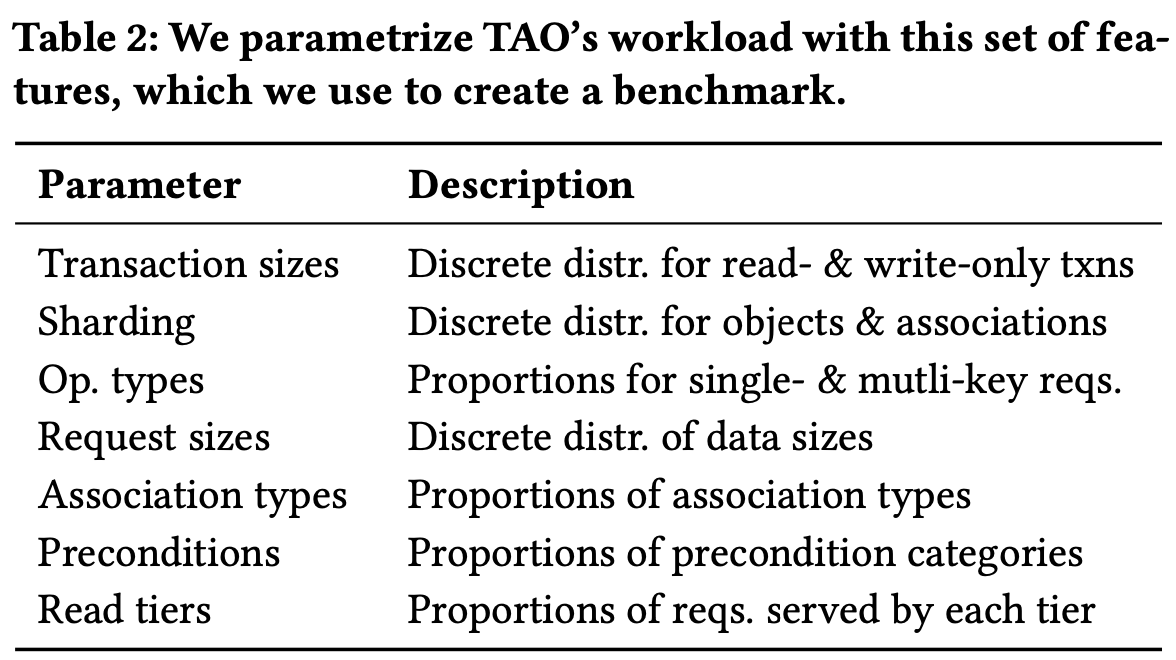
The small set of parameters in Table 2 is identified as sufficient to fully characterize the social network workload.
TAOBench
The TAOBench API consists of:
- read(key): Read a record
- read_txn(keys): Read a group of records atomically
- write(key,[preconditions]): Write to a record, optionally with a set of preconditions
- write_txn(keys,[preconditions]): Write to a group of records atomically, optionally with a set of preconditions


Facebook's use of TAOBench
I liked this section a lot. It turns out the biggest customer/beneficiary from TAOBench has been Facebook teams. Maybe this is not surprising. Due to the brutal long tails on the operation response times, slight changes in access patterns in an application may make or break that application. So it is very useful to test applications with TAOBench before deploying them on TAO.
A Facebook application team used TAOBench to evaluate the impact of adding a new transaction use case. A limited rollout to internal test users revealed the same breakdown of errors, demonstrating that TAOBench is able to successfully anticipate production issues (stemming from 26.2% increase in lock conflicts).
In another use case, engineers wanted to understand how TAO would perform if locks were held for extended periods of time (e.g., due to network delays, regional overload, or disaster recovery). Using TAOBench, they were able to quickly evaluate a representative workload.
Engineers also identified that adding a new operation on TAO could reduce preconditioned error rates by enabling the read and preconditioned write to be completed in the primary region database. For example, TAO currently supports a counter increment API (within the object update operation) that allows the read and subsequent write to be completed by the TAO writer in the primary region of the key rather than by a remote TAO client or writer. This decreases the likelihood that the read will return stale information, enabling higher success rates for the increment. TAOBench will enable engineers to explore specific use cases in detail and measure the impact of adding new APIs.
Benchmarking distributed databases
The paper applies TAOBench on five widely used distributed databases (Cloud Spanner, CockroachDB, PlanetScale, TiDB, YugabyteDB). These databases don't provide the same isolation levels. Spanner supports Strict Serializability, CockroachDB supports Serializability, and YugabyteDB supports Snapshot Isolation (SI) and Serializability. TiDB implements optimistic and pessimistic locking protocols to provide Read Committed, Repeatable Read, and SI. PlanetScale supports sharded MySQL instances with varying isolation levels including serializability within a shard and Read Committed across shards.

I really like that TAOBench provides real-world production workload, and it also helps express data colocation preferences and constraints. But the workload comes from social network usage. The underlying system is a three-tiered architecture, consisting of CSC-TAO-MySQL, with bimodal operation skew, and this likely affects the op-types, transaction sizes, request-sizes of the workload characterization. An OLTP system with SQL would likely have very different workload patterns concerning op-types, transaction sizes and request-sizes. So I don't think TAOBench is a great benchmark for a distributed transactional database.





Comments