Calvin: Fast Distributed Transactions for Partitioned Database Systems
The Calvin paper appeared in Sigmod 2012. I had read this paper before, and seen it covered in a reading group, but I never got to write a post about it, and I'm remedying that today.
I think the name Calvin comes as a pun on the predestination doctrine in Calvinism. Calvin is all about pre-ordering transactions in logs in batches, and then deterministically executing this log in the same order in replicas. The key technical feature that allows Calvin scalability in the face of distributed transactions is a deterministic ordering/locking mechanism that enables the elimination of distributed commit protocols. Since the schedulers get a good look of which transactions are coming next in this log, they can perform optimizations by pulling some independent transactions locally and executing them in parallel in worker partitions with no ill effect. Calvin achieves good performance thanks to the batching and optimizations pulled by the schedulers by looking ahead to transactions in the log. The downsides are the loss of conversational transaction execution as in SQL and high latency due to this batch based processing.
System architecture
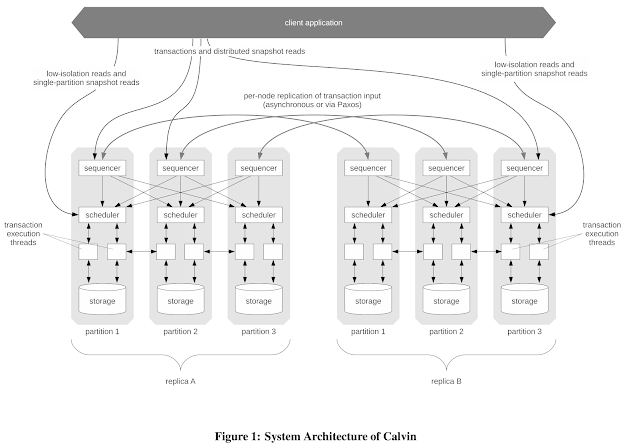
Calvin does full replication. Each replica is a full replica. (It is possible to do partial replication, but that is later developed/explained in the SLOG paper, VLDB 2019).
In Calvin, there is a master replica, which exports sequenced log to the other replicas. The other replicas then follow/execute the log, in the same deterministic way as the master replica and this makes a good demonstration of state-machine replication (SMR) in action.
Let's focus on the master replica then. Say this is replica A in the figure. Within this full replica A, there are partitioned schedulers/workers, and they work in parallel over key-range partitions assigned to themselves.
The sequencing layer intercepts transactional inputs and places them into a global transactional input sequence (log): this sequence will be the order of transactions to which all replicas will ensure serial equivalence during their execution.
The scheduling layer orchestrates transaction execution using a deterministic locking scheme to guarantee equivalence to the serial order specified by the sequencing layer while allowing transactions to be executed concurrently by a pool of transaction execution threads.
Calvin divides time into 10-millisecond epochs during which every sequencer component collects transaction requests from clients. At the end of each epoch, all requests that have arrived at a sequencer node are compiled into a batch. Given that there are multiple sequencers, how do the schedulers deduce a single order out of them? Each scheduler uses the same deterministic order (in a deterministic, round-robin manner say using ascending order of sequencer ids) and append them together and achieve the same log.
Scheduler and concurrency control
The schedulers then process the log. Recall that from this point onward, that is in the processing of the one true log provided, the follower replicas are performing the same deterministic execution/processing as the master replica as per state-machine replication approach.
Calvin's deterministic lock manager is key-range partitioned across schedulers, and each partition's scheduler is only responsible for locking records that are stored at that partition's storage component--even for transactions that access records stored on other nodes. The locking protocol resembles strict two-phase locking, with two extra rules: If any pair of transactions A and B both requests exclusive locks on a local record R, then whichever transaction comes first in the global order must acquire the lock on R first. The lock manager must grant each lock to requesting transactions strictly in the order in which those transactions requested the lock. This two phase locking is providing concurrency control across partition nodes within the replica.
The paper does not talk about the lock ordering algorithm which allows the partitioned workers to execute independent transactions (transactions in the log that don't share locks) while maintaining equivalence to the predetermined serial order. That lock ordering algorithm is of interest itself and is explained in another paper.
Once a transaction has acquired all of its locks under this protocol (and can therefore be safely executed in its entirety) it is handed off to a worker thread to be executed. Each actual transaction execution by a worker thread proceeds in five phases:
- Read/write set analysis. The first thing a transaction execution thread does when handed a transaction request is analyze the transaction's read and write sets, noting the elements of the read and write sets that are stored locally in the partition on which the thread is executing. The thread then determines the set of participating partitions at which elements of the write set are stored. These nodes are called active participants in the transaction; participating nodes at which only elements of the read set are stored are called passive participants.
- Perform local reads. Next, the worker thread looks up the values of all records in the read set that are stored locally.
- Serve remote reads. All results from the local read phase are forwarded to counterpart worker threads on every actively participating node. Since passive participants do not modify any data, they need not execute the actual transaction code, and therefore do not have to collect any remote read results. If the worker thread is executing at a passively participating node, then it is finished after this phase.
- Collect remote read results. If the worker thread is executing at an actively participating node, then it must execute transaction code, and thus it must first acquire all read results--both the results of local reads (acquired in the second phase) and the results of remote reads (forwarded appropriately by every participating node during the third phase). In this phase, the worker thread collects the latter set of read results.
- Transaction logic execution and applying writes. Once the worker thread has collected all read results, it proceeds to execute all transaction logic, applying any local writes. Nonlocal writes can be ignored, since they will be viewed as local writes by the counterpart transaction execution thread at the appropriate node, and applied there.
Note that a worker thread can't do a remote write, the corresponding partition of the replica needs to do that as local write. So, that partition also executes the same transaction, again deterministically, through local read, remote read, followed by its portion of the local write phases. This seems wasteful work, but it is unavoidable in the Calvin model.
Since Calvin is deterministic, the system is constrained to respect whatever order the sequencer chooses. This introduces a challenge for a transaction stalling on disk access, and delaying the transactions dependent on this one. Calvin tries to mitigate the impact of stalling waiting for disk access by trying to ensure that transactions aren't holding locks and waiting on disk I/O. Thus, any time a sequencer component receives a request for a transaction that may incur a disk stall, it introduces an artificial delay before forwarding the transaction request to the scheduling layer and meanwhile sends requests to all relevant storage components to "warm up" the disk-resident records that the transaction will access. If the artificial delay is greater than or equal to the time it takes to bring all the disk-resident records into memory, then when the transaction is actually executed, it will access only memory-resident data.
Getting the disk I/O latency timing is very hard. But in the evaluation in the paper, Calvin was tuned so that at least 99% of disk-accessing transactions were scheduled after their corresponding pre-fetching requests had completed. A VLDB 2017 paper, called "An Evaluation of Distributed Concurrency Control", evaluates performance of optimistic concurrency control, pessimistic locking and Calvin. It finds that for Calvin, the errors in delay estimation/scheduling is where the main performance loss comes from. I will cover that paper soon.
Evaluation results
Speaking of evaluation results, the paper evaluates Calvin using a TPC-C benchmark as well as a microbenchmark they created. Figure 4 and 5 show some results.


Throughput results for Calvin are very good, especially when most transactions are partition-local (non-distributed) transactions. But as we mentioned before, the downsides are the loss of conversational transaction execution as in SQL and high latency due to this batch based processing.
Calvin Programming API
As the price of determinism, Calvin can only do non-conversational transactions. Transactions which must perform reads in order to determine their full read/write sets (which we term dependent transactions) are not natively supported in Calvin since Calvin’s deterministic locking protocol requires advance knowledge of all transactions’ read/write sets before transaction execution can begin. Instead, Calvin supports a scheme called Optimistic Lock Location Prediction (OLLP). The idea is for dependent transactions to be preceded by an inexpensive, low-isolation, unreplicated, read-only reconnaissance query that performs all the necessary reads to discover the transaction's full read/write set. The actual transaction is then sent to be added to the global sequence and executed, using the reconnaissance query's results for its read/write set. Because it is possible for the records read by the reconnaissance query (and therefore the actual transaction's read/write set) to have changed between the execution of the reconnaissance query and the execution of the actual transaction, the read results must be rechecked, and the process have to may be (deterministically) restarted if the "reconnoitered" read/write set is no longer valid.
The determinism idea is very interesting and promising, but Calvin's API will be a deal-breaker for many users accustomed to SQL. To get a sense of this idea, you can check FaunaDB, which implements Calvin. It uses a simple query API called FQL, and provides a CRUD API.
Fault-tolerance
Last but not least, let's discuss fault-tolerance in Calvin. Partitions in replicas are organized into replication groups, each of which contains all replicas of a particular partition. In the deployment in Figure 1, for example, partition 1 in replica A and partition 1 in replica B would together form one replication group. Calvin supports Paxos-based synchronous replication of transactional inputs. In this mode, all sequencers within a replication group use Paxos to agree on a combined batch of transaction requests for each epoch.
I have some questions about how a sequencer Paxos group across replicas works. There is a master replica, and I think we expect all Paxos replica leader partition-sequencers to be located at this master replica. What if one of them has a problem and another leader is selected. For example, the Paxos leaders A1, A2, A3 now becomes A1, B2, A3. How does the execution continue this way? How is log sequence constructed. Where does the requests go? Do all requests go to A or some go at B? I guess the replicas maybe sharing requests through Paxos as well rather than all requests going to the master replica. But I guess that would require another round, where every replica share requests first? Instead of this complexity, wouldn't it make more sense to fail-over at the replica level?
As for fault-tolerance after the determination of the log, the paper gives a simple story. If there is a replica node performing the exact same operations in parallel to a failed node, however, then other nodes that depend on communication with the afflicted node to execute a transaction need not wait for the failed node to recover back to its original state—rather they can make requests to the replica node for any data needed for the current or future transactions. Furthermore, the transaction can be committed since the replica node was able to complete the transaction, and the failed node will eventually be able to complete the transaction upon recovery.





Comments