RAMP-TAO: Layering Atomic Transactions on Facebook’s Online TAO Data Store (VLDB'21)
This paper won the Best Industry Paper Award at VLDB 2021. I really like the paper. It provides a good amalgamation of database and distributed system techniques!
This paper is a followup to several previous paper some of the authors on this team had, including "Scalable atomic visibility with RAMP transactions", "Highly Available Transactions", and "Coordination avoidance". If we squint a bit more, we can say that the origins of the theme goes back to the "Probabilistically Bounded Staleness (PBS)" paper by Peter Bailis, et al. Peter found a gold mine with the PBS work. His observation that practical systems already have good freshness/consistency properties powered all of his follow-up work. This is an optimistic/opportunistic message. The theory of distributed systems and databases put most of their effort into the worst case scenario, but things are often not that bad in practice.
I like this research-continuity. We should have more of this. Not just one paper, followup. Slow research.
The paper covers a lot of ground. So this is going to be a long but fun ride. Here is how we'll do this. We will discuss Facebook's online TAO graph datastore system first. Then we will discuss the motivation for adding a read transaction API to TAO, and what would be the best isolation level for that. Then we discuss the RAMP-TAO protocol design, implementation, and evaluation. We will conclude with discussion of interesting followup points.
Motivation
TAO summary
TAO is Facebook's eventually-consistent, read-optimized, geo-distributed data store that provides online social graph access. TAO serves over ten billion reads and tens of millions of writes per second on a changing data set of many petabytes.
TAO prioritizes low-latency, scalable operations, and hence opts for weaker consistency and isolation models to serve its demanding, read-dominant workloads. TAO is basically 2-level memcached architecture layered over a statically-sharded MySQL database, as first discussed in NSDI'13 paper. MySQL replicas in each shard are kept in sync with leader/follower replication.
TAO provides point get, range, and count queries, as well as operations to create, update, and delete objects (nodes) and associations (edges). Reads are first sent to the cache layer, which aims to serve as many queries as possible via cache hits. On a cache miss, the cache is updated with data from the storage layer. Writes are forwarded to the leader for a shard, and eventually replicated to followers.
Need for transactions
Over time applications at Facebook shifted from directly accessing TAO to usign a higher-level query framework, Ent. Product developers have increasingly desired transactional semantics to avoid having to handle partial failures.
This is a universal law of database systems. Every popular data store attempts to expand until it can support transactions. We have seen, time and again, retroactive addition of transactional semantics to popular data stores. Cassandra 2.0 has added failure-atomic transactions. DynamoDB started to offer ACID transactions that use a centralized transaction coordinator. MongoDB included transactions that support Snapshot Isolation.
In accord with this law, TAO added failure-atomic write transactions, and this paper details how atomically-visible read transactions (i.e., reads observe either all or none of a transaction's operations) can be layered on top.
Fractured reads and atomic visibility
Not that easy cowboy!
For failure atomicity, TAO uses a 2PC write protocol, with background repair. While this approach ensures that writes are failure atomic (all writes succeed or none of them do), it does not provide atomic visibility (“all of a transactions updates are visible or none of them are”), as the writes from a stalled transaction will be partially visible.
Secondly, under TAO's eventual consistency, a naive batched query can observe fractured reads --reads that capture only part of a write transaction's updates before these updates are fully replicated. Two keys x, y used in a transaction may be assigned to two different MySQL shards for replication. Since writes to different shards are replicated independently, it is possible that x is updated in its shard, but y is not updated yet. Eventually all of the writes will be reflected in a copy of the dataset receiving these updates. In the meantime, it is possible for only some of the writes to be reflected in the dataset.
Due to TAO's scale and storage constraints, we want to avoid coordination and minimize memory overhead. The atomic visibility must also be cache-friendly, hot-spot tolerant, and should only incur overhead for applications that opt in (rather than requiring every application to pay a performance penalty)
Analysis
At this point, the paper goes into analysis mode to figure out how frequent these fractured-read anomalies occur in TAO, and how long these anomalies can persist. This analysis then informs how the read transactions should be designed and implemented.
The experiments in the paper show that these anomalies occur 1 out of every 1,500 read batches. Given the size of TAO's workload, this rate is significant in practice.
They measured the time between when each write transaction starts and when the subsequent read transaction begins. They found that 45% of these fractured reads persist for only a short period of time (i.e., naively retrying within a few seconds resolves these anomalies). These short-lasting anomalies occur when read and write transactions begin within 500ms of each other. For these atomic visibility violations, their corresponding write transactions were all successful. In other words, these were transient anomalies due to replication delays.
The other 55% of these atomic visibility violations could not be fixed within a short retry window and last up to 13 seconds. For this set of anomalies, their overlapping write transactions needed to undergo the 2PC failure recovery process, during which read anomalies persisted.
What did we learn? Since TAO ensures that all data is eventually consistent, we only need to guard against fractured reads for recent, transactionally updated data. How very reminiscent of the PBS work.
Isolation model
In light of this analysis and design constraints, we have one more task to finish before we can start the design of the read transaction API. We should decide on the isolation model to use.
The Jepsen site gives a great overview of the isolation/consistency models and shows the relationship between consistency models. The chart is clickable to give details about each consistency model.
Many databases offer weak isolation levels, which enable greater concurrency and improved performance. Industrial systems such as BigTable, Espresso, Manhattan, and Voldemort provide Read Uncommitted isolation in which writes to each object are totally ordered, but this order can differ per replica.
A range of systems have been built to ensure stronger isolation levels at the cost of unavailability and increased latency. Snapshot isolation is offered by many systems, including Oracle, SAP-Hana, SQL-Server, CockroachDB. Serializability is another popular choice, found in FaunaDB, G-Store, H- Store, L-Store, MDCC, Megastore, Spanner, SLOG, and TAPIR.
The paper considers whether a Snapshot Isolation, Read Atomic isolation, or Read Uncommitted isolation model would best address this. There are two competing requirements to consider for these transactions:
1. solve the requirement of eliminating atomic visibility violations
2. maintain the performance of the existing read-heavy workloads served by TAO
Snapshot Isolation solves requirement 1. It provides point-in-time snapshots of a database useful for analytical queries, which TAO is not focused on supporting. This may conflict with requirement 2.
Read Committed "prevents access to uncommitted or intermediate versions of data", but it is possible for TAO transactions to be committed, but not replicated to each individual key's shard. So it doesn't solve requirement 1, as it doesn't prevent fractured reads.
They choose Read Atomic isolation, which solves requirement 1, with very little overhead using a bolt-on consistency protocol, so it also satisfies requirement 2.
The original RAMP paper (Sigmod 2014) was the first work to explicitly address Read Atomic isolation. Read Atomic isolation sits between Read Committed and Snapshot Isolation in terms of strength, and provides atomic visibility while maintaining scalability. The dependency set required for Read Atomic isolation is bounded to the write sets of data items in the same write transactions.
Let's discuss the RAMP-TAO protocol now to see how they can ensure Read Atomic isolation while maintaining availability and scalability.
RAMP-TAO protocol
Ramping up from RAMP to RAMP-TAO
To implement Read Atomic isolation, the authors turn to the original RAMP protocol. Unfortunately, the original RAMP implementation can not be directly applied to TAO. The biggest challenge is that RAMP assumes multiple versions of data is available, but TAO maintains a single version for each row.
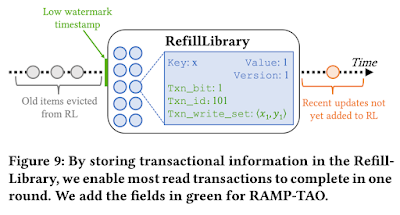
The team addresses this "multiversioning" challenge by modifying an existing piece of TAO called the RefillLibrary. The RefillLibrary is a metadata buffer that records recent writes within TAO. It stores approximately 3 minutes of writes from all regions. By including additional metadata about whether items in the buffer were impacted by write transactions, RAMP-TAO can leverage this RefillLibrary to ensure that the system doesn't violate atomic visibility as follows.
When a read happens, TAO first checks whether the items being read are in the RefillLibrary. If any items are in the RefillLibrary and are marked as being written in a transaction, the caller uses this metadata to check atomic visibility as we discuss in the fast-path of RAMP-TAO protocol explanation.
If there is not a corresponding element in the RefillLibrary for an item, either it has been evicted (aged out) or it was updated too recently and has not been replicated to the local cache. To distinguish between these two cases, we fetch and compare the logical timestamp of the oldest data item (the low watermark timestamp) in the RefillLibrary with that of the data items being read. If the items are older than the low watermark timestamp of the RefillLibrary, they must have been evicted from the buffer, and the writes that updated these items have already been globally replicated. Otherwise, our local RefillLibrary does not have the most recent information and must fetch it from the database (as discussed in the slow path in the TAO-RAMP algorithm).
Accessing transaction metadata
We are now almost ready to discuss the RAMP-TAO protocol, but let's discuss this detail we omitted earlier about how transaction metadata is stored on the database side. To minimize the overhead of storing metadata for the large majority of applications that did not use transactions, they opted to store metadata in the database to maximize cache capacity for serving requests. In particular, they decided to store metadata “out-of-line” in a separate table within the database instead of inline with each row to avoid write amplification. This table holds only information on participating shards rather than specific data items to further reduce storage overhead. Figure 8 depicts this transaction metadata placement.
RAMP-TAO protocol

There are two primary paths that read requests in RAMP-TAO take: the fast path and the slow path. The fast path happens in one round - the clients issue parallel read requests, and the returned data doesn't reflect the partial result of an in-progress transaction. This is in Figure 10, and corresponds to Lines 8-9 in the algorithm. This constitutes an overwhelming majority of cases as analysis showed.


For read transactions that contain recently updated transactional data items, RAMP-TAO uses the full write set for each item to determine atomic visibility (lines 13–21, and Figure 11). The RefillLibrary stores transaction metadata for the transaction id, timestamp, and participating keys. By making this information cacheable, they facilitate hot spot tolerance for read transactions and avoid several round trips to the database. This metadata is fetched in the first round read alongside the transactional bit, and RAMP-TAO uses the write sets to detect atomic visibility violations. If this information is not available in the RefillLibrary, they obtain it from the database. However, this extra query is rarely needed because the buffer is almost always up-to-date with the cache. Furthermore, they can amortize the cost of these metadata reads across subsequent TAO queries. To recap, TAO-read only reads from the cache. But in slow path this cache read waits to fetch data from the database.
Unimplemented optimization
The primary challenge from the lack of multiversioning is read termination. The RefillLibrary's limited retention of multiple versions decreases the chance of nontermination. However, RAMP-TAO reads of the requested versions (line 26) may be hindered by in-progress write transactions or asynchronous replication. To avoid that, they present an optimization. Instead of having TAO always return the newest available versions (line 26), we can ask the system to return slightly older ones to satisfy atomic visibility. The main advantage of trying to obtain less up-to-date versions is that the RefillLibrary will almost certainly have these items. This strategy enables RAMP-TAO to terminate as long as the older versions are still in the RefillLibrary after the first round read. Since applications already tolerate stale read results under TAO's eventual consistency, returning an older, yet atomically visible result is preferable to the possible increase in latency and number of rounds while trying fetch the most recent versions.
With this optimization, read termination is almost always guaranteed. For the extreme cases in which the RefillLibrary does not have the necessary versions (e.g., the requested version is not yet replicated but previous versions have been evicted), RAMP-TAO falls back to reading from the single-versioned database to obtain the latest version. If the versions from the database still does not satisfy atomic visibility, we either retry the reads with a backoff and timeout or hold locks on contended keys during reads to guarantee termination, although we have not found the need to do so. In these exceedingly rare cases, they opt to provide a practical solution for termination: the transaction fails and it is up to the client to retry. However, the system never returns anomalies to the client
Evaluation summary

While TAO does not provide full multiversioning, they extend the RefillLibrary to store multiple versions of recent, transactionally-updated data items. The memory impact of this change is small given that the RefillLibrary already stores 3 minutes of recent writes. Under current workloads, 3% of writes are transactional, and at most 14% of additional versions need to be stored for these updates within the RefillLibrary’s retention window. Thus, keeping multiple versions in the buffer would lead to a 0.42% overhead with existing traffic. In other words, even in the worst case, the RefillLibrary only needs to store less than one additional version, on average, per transactional data item.
Discussion
Incremental and on-demand addition of stronger guarantees
RAMP-TAO takes the "bolt-on" approach to stronger transactional guarantees. They prevent transactions from interfering with TAO's availability, durability, and replication processes, retaining the reliability and efficiency of the system. Only applications that need stronger guarantees incur the resulting performance costs. Existing applications that don't make use of transactional semantics parallelize requests to TAO and use whatever the database returns, even if the result reflects state from an in-progress transaction.
Optimization for bidirectional associations
Given the ubiquity of bidirectional associations in their graph data model, they put in work to ensure the protocol is especially efficient for these pairs of edges at scale. Bidirectional association writes are considered a special category of write transactions, since they always involve two specific keys (the forward and the inverse edges). Most of these writes do not have preconditions like uniqueness, which means they do not need the first phase of 2PC—the committed edge of either side serves as a persisted record of that transaction. This obviates need for storing transactional metadata for most writes to these paired edges.
On the read side, they optimize for the case when a read transaction includes a pair of bidirectional associations. Since both sides contain the same data and metadata (logical timestamp), they can use the results of one edge to repair the other. When an anomaly is detected, RAMP-TAO simply replaces the data in the older side with the information in its more up-to-date inverse. This additional processing is purely local. Thus, under the RAMP-TAO protocol, bidirectional association reads always complete in one round.





Comments