Graviton2 and Graviton3
What do modern cloud workloads look like? And what does that have to do with new chip designs?
I found these gems in Peter DeSantis's ReInvent20 and ReInvent21 talks. These talks are very informative and educational. Me likey! The speakers at ReInvent are not just introducing new products/services, but they are also explaining the thought processes behind them.
To come up with this summary, I edited the YouTube video transcripts slightly (mostly shortening it). The presentation narratives have been really well planned, so this makes a good read I think.
Graviton2
This part is from the ReInvent2020 talk from Peter DeSantis.
Graviton2 is the best performing general purpose processor in our cloud by a wide margin. It also offers significantly lower cost. And it's also the most power efficient processor we've ever deployed.
Our plan was to build a processor that was optimized for AWS and modern cloud workloads. But, what do modern cloud workloads look like?
Let's start by looking at what a modern processor looks like. For a long time, the main difference between one processor generation and the next was the speed of the processor. And this was great while it lasted. But about 15 years ago, this all changed. New processors continued to improve their performance but not nearly as quickly as they had in the past.
Instead, new processors started adding cores. You can think of a core like a mini processor on the chip. Each core on the chip can work independently and at the same time as all the other cores. This means that if you can divide your work up, you can get that work done in parallel. Processors went from one core to two and then four.
So, how did workloads adapt to this new reality? Well, the easiest way to take advantage of cores is to run more independent applications on the server and modern operating systems have got very good at scheduling and managing multiple processes on high core systems. Another approach is multi-threaded applications. Multi-threaded applications allow builders to have the appearance of scaling up while taking advantage of parallel execution.
While scale out computing has evolved to take advantage of higher core processors; processor designers have never really abandoned the old world. Modern processors have tried to have it both ways, catering to both legacy applications and modern scale out applications. And this makes sense if you think about it. As I mentioned, producing a new processor can cost hundreds of millions of dollars and the way you justify that sort of large upfront investment is by targeting the broadest option possible. So, modern mini core processors have unsurprisingly tried to appeal to both legacy applications and modern scale out applications.
(In the ReInvent21 talk, Peter referred back to this with the El Camino analogy. El Camino tries to be both a passenger car and pickup truck, and as a result not being very good at either.)
Cores got so big and complex that it was hard to keep everything utilized. And the last thing you want is transistors on your processor doing nothing. To work around this limitation, processor designers invented a new concept called simultaneous multi-threading or SMT. SMT allows a single core to work on multiple tasks. Each task is called a thread. Threads share the core so SMT doesn’t double your performance but it does allow you to take use of that big core and maybe improves your performance by 20-30%. But SMT also has drawbacks. The biggest drawback of SMT is it introduces overhead and performance variability. And because each core has to work on multiple tasks, each task’s performance is dependent on what the other tasks are doing around it. Workloads can contend for the same resources like cache space slowing down the other threads on the same core. There are also security concerns with SMT. The side channel attacks try to use SMT to inappropriately share and access information from one thread to another. EC2 doesn't share threads from the same processor core across multiple customers to ensure customers are never exposed to these potential SMT side channel attacks.
And SMT isn't the only way processor designers have tried to compensate for overly large and complex cores. The only thing worse than idle transistors is idle transistors that use power. So, modern cores have complex power management functions that attempt to turn off or turn down parts of the processor to manage power usage. The problem is, these power management features introduce even more performance variability. Basically, all sort of things can happen to your application and you have no control over it.
And in this context, you can now understand how Graviton2 is different. The first thing we did with Graviton2 was focus on making sure that each core delivered the most real-world performance for modern cloud workloads. When I say real-world performance, I mean better performance on actual workloads. Not things that lead to better spec sheets stats like processor frequency or performance micro benchmarks which don't capture real-world performance. We used our experience running real scale out applications to identify where we needed to add capabilities to assure optimal performance without making our cores too bloated.
Second, we designed Graviton2 with as many independent cores as possible. When I say independent, Graviton2 cores are designed to perform consistently. No overlapping SMT threads. No complex power state transitions. Therefore, you get no unexpected throttling, just consistent performance. And some of our design choices actually help us with both of these goals.
Let me give you an example. Caches help your cores run fast by hiding the fact that system memory runs hundreds of times slower than the processor. Processors often use several layers of caches. Some are slower and shared by all the cores. And some are local to a core and run much faster. With Graviton2, one of the things we prioritized was large core local caches. In fact, the core local L1 caches on Graviton2 are twice as large as the current generation x86 processors. And because we don't have SMT, this whole cache is dedicated to a single execution thread and not shared by competing execution threads. And this means that each Graviton2 core has four times the local L1 caching as SMT enabled x86 processors. This means each core can execute faster and with less variability.
Because Graviton2 is an Arm processor, a lot of people will assume that Graviton2 will perform good at front-end applications, but they doubt it can perform well enough for serious I/O intensive back-end applications. But this is not the case. So, let’s look at a Postgres database workload performing a standard database benchmark called HammerDB. We are going to compare Graviton2 with the m5 instances. As we consider the larger m5 instance sizes (blue color bars), you can see right away the scaling there isn't very good. There are a few reasons for this flattening. But it mostly comes down to sharing memory across two different processors, and that sharing adds latency and variability to the memory access. And like all variability, this makes it hard for scale-out applications to scale efficiently.
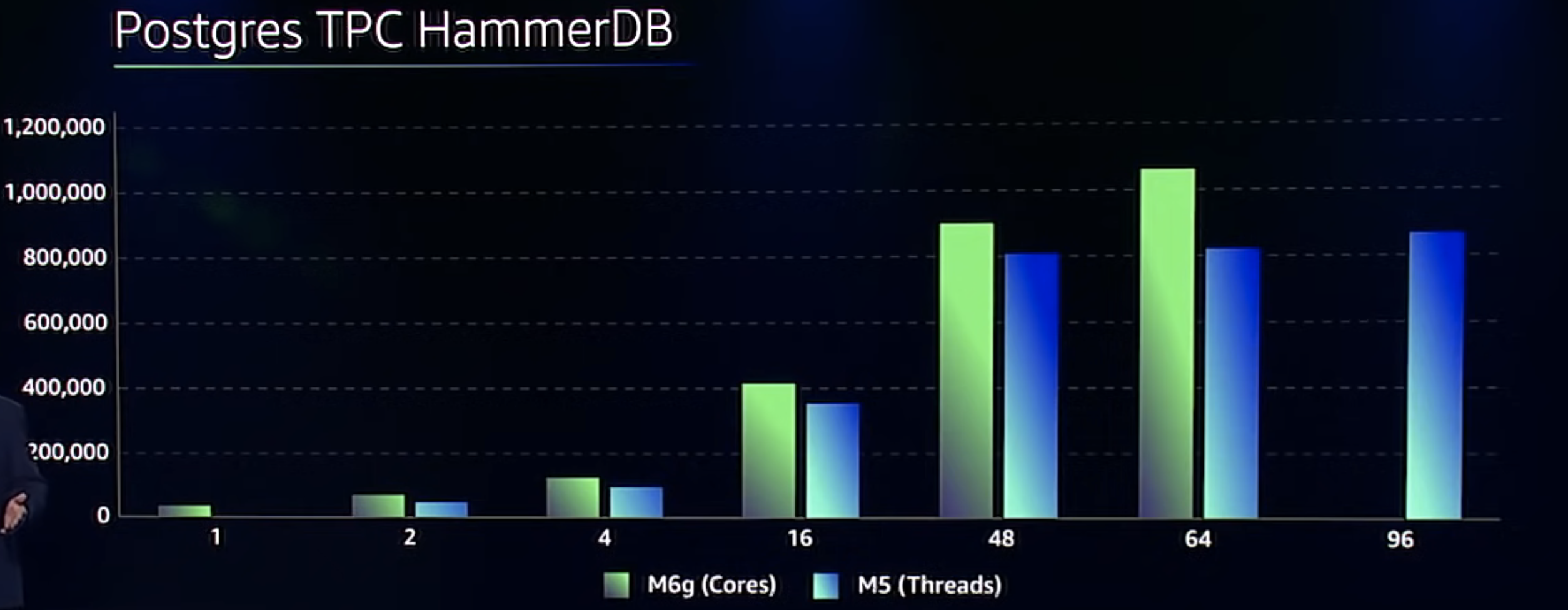
Let's now look at Graviton (green color bars). Here we can see the M6g instance on the same benchmark. You can see that M6g delivers better absolute performance at every size. But that’s not all. First you see the M6g scales almost linearly all the way up to the 64 core largest instance size. And by the time you get to 48 cores, you have better absolute performance that even the largest m5 instance with twice as many threads. And for your most demanding workloads the 64 core M6g instance provides over 20% better absolute performance than any m5 instance.
But this isn’t the whole story. Things get even better when we factor in the lower cost of the M6g. The larger sized instances are nearly 60% lower cost. And because the M6g scales down better than a threaded processor, you can save even more with the small instance, over 80% on this workload.
Graviton3
This part is from Peter's ReInvent21 talk.
We knew that if we built a processor that was optimized specifically for modern workloads that we could dramatically improve the performance, reduce the cost, and increase the efficiency of the vast majority of workloads in the cloud. And that's what we did with Graviton.
A lot happened over the last year so let me get you quickly caught up. We released Graviton optimized versions of our most popular AWS managed services. We also released Graviton support for Fargate and Lambda, extending the benefits of Graviton to serverless computing. ...
So where do we go from here how do we build on the success of Graviton2? We are previewing Graviton3, which will provide at least 25 percent improved performance for most workloads. Remember Graviton 2 which was released less than 18 months ago already provides the best performance for many workloads so this is another big jump.
So how did we accomplish that?

Here are the sticker stats they may look impressive they are but as I mentioned last year and this bears repeating: the most important thing we're doing with graviton is staying laser focused on the performance of real workloads, your workloads! When you're designing a new chip it can be tempting to optimize the chip for these sticker stats like processor frequency or core count and while these things are important they're not the end goal. The end goal is the best performance and the lowest cost for real workloads. And I'm going to show you how we do that with Graviton3. And I'm also going to show you how if you focus on these sticker stats you can actually be led astray.
When you look to make a processor faster, the first thing that probably comes to mind is to increase the processor frequency. For many years we were spoiled because each new generation of processor ran at a higher frequency than the previous generation, and higher frequency means the processor runs faster. That's delightful, because magically everything just runs faster. The problem is when you increase frequency of a processor you need to increase the amount of power that you're sending to the chip. Up until about 15 years ago, every new generation of silicon technology allowed transistors to be operated at lower and lower voltages. This was a property called Dennard scaling. Dennard scaling made processors more power efficient and enable processor frequencies to be increased without raising the power of the overall processor. But Dennard scaling has slowed down as we've approached the minimum voltage threshold of a functional transistor in silicon. So now if we want to keep increasing processor frequency, we need to increase the power on a chip. Maybe you've heard about or even tried overclocking a CPU. To overclock a CPU you need to feed a lot more power into the server, and that means you get a lot more waste heat, so you need to find a way to cool the processor. This is not a great idea in a data center. Higher power means higher cost. It means more heat. And it means lower efficiency.
So how do we increase the performance of graviton without reducing power efficiency? The answer is we make the core wider! A wider core is able to do more work per cycle. So instead of increasing the number of cycles per second, we increase the amount of work that you can do in each cycle.
With Graviton3 we've increased the width of the core in a number of ways. One example is we've increased the number of instructions that each core can work on concurrently from five to eight instructions per cycle. This is called instruction execution parallelism. How well each application is going to do with this additional core width is going to vary, and it's dependent on really clever compilation, but our testing tells us that most workloads will see at least 25% faster performance and some workloads like Nginx are seeing 60% performance improvement. Higher instruction execution parallelism is not the only way to increase performance. By making things wider you can also increase the width of the data that you're processing. A great example of this is doing vector operations. Graviton3 doubles the size of the vectors that can be operated on in a single cycle with one of these vector operations and this will have significant impact on workloads like video encoding and encryption.
Adding more cores is an effective way of improving processor performance and generally you want as many cores as you can fit. But you need to be careful here as well, because there are trade-offs that impact the application. When we looked closely at real workloads running on Graviton2, what we saw is that most workloads could actually run more efficiently if they had more memory bandwidth and lower latency access to memory. Now that isn't surprising modern cloud workloads are using more memory and becoming more more sensitive to memory latency so rather than using our extra transistors to pack more cores onto Graviton3, we decided to use our transistors to improve memory performance! Graviton2 instances already had a lot of memory bandwidth per VCPU, but we decided to add even more to Graviton3. Each Graviton3 core has 50% more memory than Graviton2. c7g powered by Graviton3 is the first cloud instance to support the new ddr5 memory standard which also improves memory performance.





Comments