SOSP19 Day 1, Debugging session
This session was the first session after lunch and had four papers on debugging in large scale systems.
Crash recovery code can be buggy and often result in catastrophic failure. Random fault injection is ineffective for detecting them as they are rarely exercised. Model checking at the code level is not feasible due to state space explosion problem. As a result, crash-recovery bugs are still widely prevalent. Note that the paper does not talk about "crush" bugs, but "crash recovery" bugs, where the recovery code interferes with normal code and causes the error.
Crashtuner introduces new approaches to automatically detect crash recovery bugs in distributed systems. The paper observes that crash-recovery bugs involve "meta-info" variables. Meta-info variables include variables denoting nodes, jobs, tasks, applications, containers, attempt, session, etc. I guess these are critical metadata. The paper might include more description for them.
The insight in the paper is that crash-recovery bugs can be easily triggered when nodes crash before reading meta-info variables and/or crash after writing meta-info variables.
Using this insight, Crashtuner inserts crash points at read/write of meta-info variables. This results in a 99.91% reduction on crash points with previous testing techniques.
They evaluated Crashtuner on Yarn, HDFS, HBase, and ZooKeeper and found 116 crash recovery bugs. 21 of these were new crash-recovery bugs (including 10 critical bugs). 60 of these bugs were already fixed.
The presentation concluded by saying that meta-info is a well-suited abstraction for distributed systems. After the presentation, I still have questions about identifying meta-info variables and what would be false-positive and false-negative rates for finding meta-info variables via heuristic definition as above.
This paper is about debugging for finding the root cause of a failure. The basic approach is to collect large number of traces (via failure reproduction and failure execution), and try to find the strongest statistical correlation with the fault, and identify this as the root cause. The paper asks the question: what is the fundamental property of root cause that allows us to build a tool to automatically identify the root cause?
The paper offers as the definition for root cause as "the most basic reason for failure, if corrected will prevent the fault from occurring." This has two parts: "if changed would result in correct execution" and "the most basic cause".
Based on this, the paper defines inflection point as the first point in the failure execution that differs from the instruction in nonfailure execution. And develops Kairux: a tool for automated root cause localization. The idea in Kairux is to construct the nonfailure execution that has the longest common prefix. To this end it uses unit tests, stitches unit test to construct nonfailure execution, and modifies existing unit test for longer common prefix. Then it uses dynamic slicing to obtain partial order.
The presentation gave a real world example from HDFS 10453, delete blockthread. It took the developer one month to figure out the root cause of the bug. Kairux does this automatically.
Kairux was evaluated on 10 cases from JVM distributed systems, including HDFS, HBase, ZooKeeper. It successfully found the root cause for 7 out the 10 cases. For the 3 unsuccessful cases, the paper claims this was because the root cause location could not be reached by modifying unit tests
This paper was similar to the previous paper in the session in that it had a heuristic insight which had applicability in a reasonably focused narrow domain. I think the tool support would be welcome by developers. Unfortunately I didn't see that the code and tool is available as opensource anywhere.
The presentation offers by asking "Can file systems be bug free?" and answers this in the negative, citing that the codebase for filesystems is massive (40K-100K) and are constantly evolving. This paper proposes to use fuzzing as an umbrella solution that unifies existing bug checkers for finding semantic bugs in filesystems.
The idea in fuzzing is to give crashes are feedback to the fuzzers. However, the challenge for finding semantic bugs using fuzzers is that semantic bugs are silent, and won't be detected. So we need a checker to go through the test cases and check for the validity of return values, and give this feedback to fuzzer.
To realize this insight, they built Hydra. Hydra is available as opensource at https://github.com/sslab-gatech/hydra
Hydra uses checker defined signals, automates input space exploration, test execution, and incorporation of test cases. Hydra is extensible via pluggable checkers for spec violation posix checker (sybilfs), for logic bugs, for memory safety bugs, and for crash consistency bug (symC3).
So far, Hydra has discovered 91 new bugs in Linux file systems, including several crash consistency bugs. Hydra also found a bug in a verified file system (FSCQ), (because it had used an unverified function in implementation).
The presenter said that Hydra generates better test cases, and the minimizer can reduce the steps in crashes from 70s to 20s. The presentation also live demoed Hydra in action with symC3.
This paper received a best paper award at SOSP19. It provides an easy push button for finding concurrency bugs.
The paper deals with thread safety violations (TSV). A thread safety violation occurs if two threads concurrently invoke two conflicting methods upon the same object. For example, the C# list datastructure has a contract that says two adds cannot be concurrent. Unfortunately thread safety violations still exist, and are hard to find via testing as they don't show up in most test runs. The presentation mentioned a major bug that lead to Bitcoin loss.
Thread safety violations are very similar to data race conditions, and it is possible to use data-race detection tools in a manually intensive process to find some of these bugs in small scale. To reduce the manual effort, it is possible to adopt dynamic data race analysis while running the program under test inputs, but these require a lot of false-positive pruning.
In a large scale, these don't work. The CloudBuild at Microsoft involves 100million tests from 4K team and upto 10K machines. At this scale, there are three challenges: integration, overhead, and false positives.
The paper presents TSVD, a scalable dynamic analysis tool. It is push button. You provide TSVD only the thread safety contract, and it finds the results with zero false positives. TSVD was deployed in Azure, and it has found more than 1000 bugs in a short time. The tool is available as opensource at https://github.com/microsoft/TSVD
To achieve zero false positive, TSVD uses a very interesting trick. A potential violation (i.e., a call site that was identified by code analysis as one that may potentially violate the thread safety contract) is retried in many test executions by injecting delays to trigger a real violation. If a real violation is found, this is a true bug. Else, it was a false-positive and is ignored.
But how do we do the analysis to identify these potentially unsafe calls to insert delays? TSVD uses another interesting trick to identify them. It looks for conflicting calls with close-by physical timestamps. It flags likely racing calls, where two conflicting calls from different threads to the same object occur within a short physical time window. This way of doing things is more efficient and scalable than trying to do a happened-before analysis and finding calls with concurrent logical timestamps. Just identify likely race calls.
OK, what if there is actual synchronization between the two potentially conflicting calls within closeby physical timestamps? Why waste energy to keep testing it to break this? Due to synchronization, this won't lead to a real bug. To avoid this they use synchronization inference (another neat trick!): If m1 synchronized before m2, a delay added to m1 leads to the same delay to m2. If this close correlation is observed in the delays, TSVD infers synchronization. This way it also infers if a program is running sequentially or not, which calls are more likely to lead to problems, etc.
They deployed TSVD at Microsoft for several months. It was given thread safety contracts of 14 system classes in C#, including list, dictionary, etc. It was tested on 1600 projects, and was run 1 or 2 times, and found 1134 thread safety violations. During the validation procedure, they found that 96% TSVs are previously unknown to developers and 47% will cause severe customer facing issues eventually.
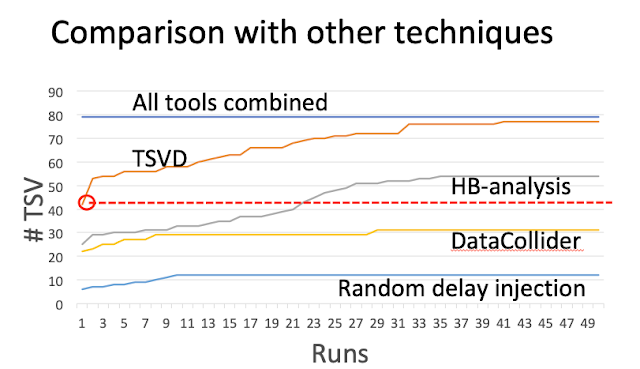
TSVD beats other approaches, including random, data collider, happened-before (hb) tracking. 96% of all violations were captured by running TSVD 50 times. And 50% violations were captured by running TSVD once! This beats other tools with little overhead.
One drawback to TSVD approach is that it may cause a false negative by adding the random delay. But when you run the tool multiple times, those missed false negatives are captured due to different random delays tried.
Yep, this paper definitely deserved a best paper award. It used three very interesting insights/heuristics to make the problem feasible/manageable, and then built a tool using these insights, and showed exhaustive evaluations of this tool.
CrashTuner: Detecting Crash Recovery Bugs in Cloud Systems via Meta-info Analysis
This paper is by Jie Lu (The Institute of Computing Technology of the Chinese Academy of Sciences), Chen Liu (The Institute of Computing Technology of the Chinese Academy of Sciences), Lian Li (The Institute of Computing Technology of the Chinese Academy of Sciences), Xiaobing Feng (The Institute of Computing Technology of the Chinese Academy of Sciences), Feng Tan (Alibaba Group), Jun Yang (Alibaba Group), Liang You (Alibaba Group).Crash recovery code can be buggy and often result in catastrophic failure. Random fault injection is ineffective for detecting them as they are rarely exercised. Model checking at the code level is not feasible due to state space explosion problem. As a result, crash-recovery bugs are still widely prevalent. Note that the paper does not talk about "crush" bugs, but "crash recovery" bugs, where the recovery code interferes with normal code and causes the error.
Crashtuner introduces new approaches to automatically detect crash recovery bugs in distributed systems. The paper observes that crash-recovery bugs involve "meta-info" variables. Meta-info variables include variables denoting nodes, jobs, tasks, applications, containers, attempt, session, etc. I guess these are critical metadata. The paper might include more description for them.
The insight in the paper is that crash-recovery bugs can be easily triggered when nodes crash before reading meta-info variables and/or crash after writing meta-info variables.
Using this insight, Crashtuner inserts crash points at read/write of meta-info variables. This results in a 99.91% reduction on crash points with previous testing techniques.
They evaluated Crashtuner on Yarn, HDFS, HBase, and ZooKeeper and found 116 crash recovery bugs. 21 of these were new crash-recovery bugs (including 10 critical bugs). 60 of these bugs were already fixed.
The presentation concluded by saying that meta-info is a well-suited abstraction for distributed systems. After the presentation, I still have questions about identifying meta-info variables and what would be false-positive and false-negative rates for finding meta-info variables via heuristic definition as above.
The Inflection Point Hypothesis: A Principled Debugging Approach for Locating the Root Cause of a Failure
This paper is by Yongle Zhang (University of Toronto), Kirk Rodrigues (University of Toronto), Yu Luo (University of Toronto), Michael Stumm (University of Toronto), Ding Yuan (University of Toronto).This paper is about debugging for finding the root cause of a failure. The basic approach is to collect large number of traces (via failure reproduction and failure execution), and try to find the strongest statistical correlation with the fault, and identify this as the root cause. The paper asks the question: what is the fundamental property of root cause that allows us to build a tool to automatically identify the root cause?
The paper offers as the definition for root cause as "the most basic reason for failure, if corrected will prevent the fault from occurring." This has two parts: "if changed would result in correct execution" and "the most basic cause".
Based on this, the paper defines inflection point as the first point in the failure execution that differs from the instruction in nonfailure execution. And develops Kairux: a tool for automated root cause localization. The idea in Kairux is to construct the nonfailure execution that has the longest common prefix. To this end it uses unit tests, stitches unit test to construct nonfailure execution, and modifies existing unit test for longer common prefix. Then it uses dynamic slicing to obtain partial order.
The presentation gave a real world example from HDFS 10453, delete blockthread. It took the developer one month to figure out the root cause of the bug. Kairux does this automatically.
Kairux was evaluated on 10 cases from JVM distributed systems, including HDFS, HBase, ZooKeeper. It successfully found the root cause for 7 out the 10 cases. For the 3 unsuccessful cases, the paper claims this was because the root cause location could not be reached by modifying unit tests
This paper was similar to the previous paper in the session in that it had a heuristic insight which had applicability in a reasonably focused narrow domain. I think the tool support would be welcome by developers. Unfortunately I didn't see that the code and tool is available as opensource anywhere.
Finding Semantic Bugs in File Systems with an Extensible Fuzzing Framework
This paper is by Seulbae Kim (Georgia Institute of Technology), Meng Xu (Georgia Institute of Technology), Sanidhya Kashyap (Georgia Institute of Technology), Jungyeon Yoon (Georgia Institute of Technology), Wen Xu (Georgia Institute of Technology), Taesoo Kim (Georgia Institute of Technology).The presentation offers by asking "Can file systems be bug free?" and answers this in the negative, citing that the codebase for filesystems is massive (40K-100K) and are constantly evolving. This paper proposes to use fuzzing as an umbrella solution that unifies existing bug checkers for finding semantic bugs in filesystems.
The idea in fuzzing is to give crashes are feedback to the fuzzers. However, the challenge for finding semantic bugs using fuzzers is that semantic bugs are silent, and won't be detected. So we need a checker to go through the test cases and check for the validity of return values, and give this feedback to fuzzer.
To realize this insight, they built Hydra. Hydra is available as opensource at https://github.com/sslab-gatech/hydra
Hydra uses checker defined signals, automates input space exploration, test execution, and incorporation of test cases. Hydra is extensible via pluggable checkers for spec violation posix checker (sybilfs), for logic bugs, for memory safety bugs, and for crash consistency bug (symC3).
So far, Hydra has discovered 91 new bugs in Linux file systems, including several crash consistency bugs. Hydra also found a bug in a verified file system (FSCQ), (because it had used an unverified function in implementation).
The presenter said that Hydra generates better test cases, and the minimizer can reduce the steps in crashes from 70s to 20s. The presentation also live demoed Hydra in action with symC3.
Efficient and Scalable Thread-Safety Violation Detection --- Finding thousands of concurrency bugs during testing
This paper is by Guangpu Li (University of Chicago), Shan Lu (University of Chicago), Madanlal Musuvathi (Microsoft Research), Suman Nath (Microsoft Research), Rohan Padhye (Berkeley).This paper received a best paper award at SOSP19. It provides an easy push button for finding concurrency bugs.
The paper deals with thread safety violations (TSV). A thread safety violation occurs if two threads concurrently invoke two conflicting methods upon the same object. For example, the C# list datastructure has a contract that says two adds cannot be concurrent. Unfortunately thread safety violations still exist, and are hard to find via testing as they don't show up in most test runs. The presentation mentioned a major bug that lead to Bitcoin loss.
Thread safety violations are very similar to data race conditions, and it is possible to use data-race detection tools in a manually intensive process to find some of these bugs in small scale. To reduce the manual effort, it is possible to adopt dynamic data race analysis while running the program under test inputs, but these require a lot of false-positive pruning.
In a large scale, these don't work. The CloudBuild at Microsoft involves 100million tests from 4K team and upto 10K machines. At this scale, there are three challenges: integration, overhead, and false positives.
The paper presents TSVD, a scalable dynamic analysis tool. It is push button. You provide TSVD only the thread safety contract, and it finds the results with zero false positives. TSVD was deployed in Azure, and it has found more than 1000 bugs in a short time. The tool is available as opensource at https://github.com/microsoft/TSVD
To achieve zero false positive, TSVD uses a very interesting trick. A potential violation (i.e., a call site that was identified by code analysis as one that may potentially violate the thread safety contract) is retried in many test executions by injecting delays to trigger a real violation. If a real violation is found, this is a true bug. Else, it was a false-positive and is ignored.
But how do we do the analysis to identify these potentially unsafe calls to insert delays? TSVD uses another interesting trick to identify them. It looks for conflicting calls with close-by physical timestamps. It flags likely racing calls, where two conflicting calls from different threads to the same object occur within a short physical time window. This way of doing things is more efficient and scalable than trying to do a happened-before analysis and finding calls with concurrent logical timestamps. Just identify likely race calls.
OK, what if there is actual synchronization between the two potentially conflicting calls within closeby physical timestamps? Why waste energy to keep testing it to break this? Due to synchronization, this won't lead to a real bug. To avoid this they use synchronization inference (another neat trick!): If m1 synchronized before m2, a delay added to m1 leads to the same delay to m2. If this close correlation is observed in the delays, TSVD infers synchronization. This way it also infers if a program is running sequentially or not, which calls are more likely to lead to problems, etc.
They deployed TSVD at Microsoft for several months. It was given thread safety contracts of 14 system classes in C#, including list, dictionary, etc. It was tested on 1600 projects, and was run 1 or 2 times, and found 1134 thread safety violations. During the validation procedure, they found that 96% TSVs are previously unknown to developers and 47% will cause severe customer facing issues eventually.
TSVD beats other approaches, including random, data collider, happened-before (hb) tracking. 96% of all violations were captured by running TSVD 50 times. And 50% violations were captured by running TSVD once! This beats other tools with little overhead.
One drawback to TSVD approach is that it may cause a false negative by adding the random delay. But when you run the tool multiple times, those missed false negatives are captured due to different random delays tried.

Yep, this paper definitely deserved a best paper award. It used three very interesting insights/heuristics to make the problem feasible/manageable, and then built a tool using these insights, and showed exhaustive evaluations of this tool.





Comments