Schema-Agnostic Indexing with Azure Cosmos DB
This VLDB'15 paper is authored by people from the Cosmos DB team and Microsoft research. The paper has "DocumentDB" in the title because DocumentDB was the project that evolved into Azure Cosmos DB. The project started in 2010 to address the developer pain-points inside Microsoft for supporting large scale applications. In 2015 the first generation of the technology was made available to Azure developers as Azure DocumentDB. It has since added many new features and introduced significant new capabilities, resulting in Azure Cosmos DB!
This paper describes the schema-agnostic indexing subsystem of Cosmos DB. By being fully schema-agnostic, Cosmos DB provides many benefits to the developers. Keeping the database schema and indexes in-sync with an application's schema is especially painful for globally distributed apps. But with a schema-agnostic database, you can iterate your app quickly without worrying of schemas or indexes. Cosmos DB automatically indexes all the data --no schema, no indexes required-- and serves queries very fast. Since no schema and index management is required, you don't have to worry about application downtime while migrating schemas either.
To achieve these, Cosmos DB natively supports JSON (JavaScript Object Notation) data model and JavaScript language directly within its database engine. This approach enables the following:
Of course the challenge is to do all of these while (1) providing predictable performance guarantees and (2) remaining cost effective. For (1), the challenges are in updating the index efficiently and synchronously against high write rates and in hitting the SLA performance guarantees as well as the configured consistency levels. For (2), the challenges are in resource governance for providing multitenancy under extremely frugal budgets: the index updates must be performed within the strict budget of system resources (CPU, memory, storage), and load balancing and relocation of replicas should be performed such that the worst-case on-disk storage overhead of the index is bounded and predictable. Please see my overview post for a high level overview of Cosmos DB. I will be diving in to the subsystems in the coming days.

A tenant starts by provisioning a database account using an Azure subscription (you can try it for free at https://azure.microsoft.com/en-us/try/cosmosdb/). The database account manages one or more databases, each of which manages a set of resources: users, permissions, and containers. In Cosmos DB, a container can be projected as a "collection, table, graph" for supporting APIs for "SQL, Table, Gremlin". In addition, a container also manages stored procedures, triggers, user defined functions (UDFs) and attachments.
Each resource is uniquely identified by a stable logical URI and is represented as a JSON document. Developers can interact with resources via HTTP (and over a stateless TCP protocol) using the standard HTTP verbs for CRUD (create, read update, delete), queries, and stored procedures.
All the data within an Azure Cosmos DB container (e.g. collection, table, graph) is horizontally partitioned and Cosmos DB transparently manages those resource partitions behind the scene. Tenants can elastically scale a resource by simply creating new resources which get partitioned (or distributed) across resource partitions automatically.

A resource partition is made highly available by a replica set across Azure regions. I talk about this global distribution next.


The service is deployed worldwide across multiple Azure regions (50+ of them). Cosmos DB is classified as a foundational service in Azure --which means it is automatically available in every Azure region including public, sovereign, and government clouds. Cosmos DB runs on clusters of machines each with dedicated local SSDs --other storage options for petabyte level data is also configurable.
Each stamp has its own fabric controller. A stamp consists of racks, each of which is built out as a separate fault domain with redundant networking and power. I will summarize the Microsoft fabric paper later.
Each machine hosts replicas corresponding to various resource partitions, which are placed and load balanced across machines in the federation. Each replica hosts an instance of the database engine, which manages the resources (e.g. documents) as well as the associated index. The database engine contains replicated state machine for coordination, the JavaScript language runtime, the query processor, and the storage and indexing subsystems responsible for transactional storage and indexing of documents.
While I won't be able to detail it in this post, Cosmos DB's unique design of resource governance underlies the core of the system: on any single machine there could be hundreds of tenants co-existing, each properly isolated (without any noisy neighbor symptoms) and resource-governed. In addition, Cosmos DB provides a consistent programming model to provision throughput across a heterogeneous set of database operations for each of the tenants at each region at any point in time while maintaining the SLAs.
The Cosmos DB database engine operates directly at the level of JSON grammar, remaining agnostic to the concept of a document schema and blurring the boundary between the structure and instance values of documents. This, in turn, enables it to automatically index documents without requiring schema or secondary indices as we see below.

The figure above shows the trees created for a document 1 and document 2. The labels are inferred from the document. A (pseudo) root node is created to parent the rest of the (actual) nodes corresponding to the labels in the document underneath. The nested data structures drive the hierarchy in the tree. Intermediate artificial nodes labeled with numeric values (e.g. 0, 1, ...) are employed for representing enumerations, array indices.
There are two possible mappings of document and the paths: a forward index mapping, which keeps a map of (document id, path) tuples, as we saw above, and an inverted index mapping, which keeps a map of (path, document id) tuples.
The inverted index provides a very efficient representation for querying. The index tree is a document which is constructed out of the union of all of the trees representing individual documents within the collection. The index tree grows over time as new documents get added or updated to the collection. In contrast to relational database indexing, there is no need for restarting indexing from scratch as new fields are introduced.

Each node of the index tree is an index entry containing the label and position values, called the term, and the ids of the documents, called the postings. The postings in the curly brackets (e.g. {1,2}) in the inverted index figure correspond to the documents (e.g., Document1 and Document2) containing the given label value. An important implication of treating both the schema labels and instance values uniformly is that everything is packed inside a big index. An instance value (still in the leaves) is not repeated, it can be in different roles across documents, with different schema labels, but it is the same value.
The inverted index looks to me as similar to the indexing structures used in a search engine in the information retrieval domain. In a sense, Cosmos DB let's you search your database for anything added to it regardless of its schema structure.
For the normalized path, the service uses a combination of partial (consisting of 3 segments) forward path representation for paths where range support is needed while following partial reverse path representation for paths needing equality (hash) support.
The query model attempts to strike a balance between functionality, efficiency, and simplicity. The database engine natively compiles and executes the SQL query statements. You can query a collection using the REST APIs or any of the client SDKs. The .NET SDK comes with a LINQ provider. Here is a query playground where you can experiment.
The below figures illustrate point querying and range querying. The inverted index allows the query to identify the documents that match the query predicate quickly. Another important implication of treating both the schema and instance values uniformly in terms of paths is that the inverted index is also a tree. Thus, the index and the results can be serialized to a valid JSON document and returned as documents themselves as they are returned in the tree representation. This enables recursing over these results with additional querying.

For the second query, a range query, GermanTax is a user defined function executed as part of query processing.

In this post, I only scratched the surface. I haven't started to write about the technical meat of the paper in the logical index organization and the physical index organization sections. These sections introduce a novel logical index layout and a latch-free log-structured storage with blind incremental updates in order to meet the strict requirements of performance (SLA-bounded) and cost effectiveness (in a multitenant environment). Bw-trees introduced by Microsoft Research, a type of B-trees, is employed as part of the physical index organization.
In order to write about those sections more confidently, I will track down the experts here on the logical and physical index organization and will try to get a crash course on these.
I realized that I am completely ignorant on this topic. But, it also appears that there aren't good explanations on this when I search for it. I will try to find more about this.
2. How do these design decisions fit with the historical trend/direction of database systems?
I found this recent article by Pat Helland very interesting: "Mind Your State for Your State of Mind". So I will plan to summarize it and try to analyze how today's design decisions fit with the historical trends/directions.
"Applications have had an interesting evolution as they have moved into the distributed and scalable world. Similarly, storage and its cousin databases have changed side by side with applications. Many times, the semantics, performance, and failure models of storage and applications do a subtle dance as they change in support of changing business requirements and environmental challenges. Adding scale to the mix has really stirred things up. This article looks at some of these issues and their impact on systems."
3. Can there be a ranking component to the search/querying that enables ranking with respect to user-defined priority? That can be useful for long running or realtime streaming query.
This paper describes the schema-agnostic indexing subsystem of Cosmos DB. By being fully schema-agnostic, Cosmos DB provides many benefits to the developers. Keeping the database schema and indexes in-sync with an application's schema is especially painful for globally distributed apps. But with a schema-agnostic database, you can iterate your app quickly without worrying of schemas or indexes. Cosmos DB automatically indexes all the data --no schema, no indexes required-- and serves queries very fast. Since no schema and index management is required, you don't have to worry about application downtime while migrating schemas either.
To achieve these, Cosmos DB natively supports JSON (JavaScript Object Notation) data model and JavaScript language directly within its database engine. This approach enables the following:
- The query language (rooted in JavaScript's type system, expression evaluation and function invocation model) supports rich relational and hierarchical queries and is exposed to developers as a SQL dialect.
- By default, the database engine automatically indexes all documents without requiring schema or secondary indexes from developers.
- The database supports transactional execution of application logic provided via stored procedures and triggers, written entirely in JavaScript.
Of course the challenge is to do all of these while (1) providing predictable performance guarantees and (2) remaining cost effective. For (1), the challenges are in updating the index efficiently and synchronously against high write rates and in hitting the SLA performance guarantees as well as the configured consistency levels. For (2), the challenges are in resource governance for providing multitenancy under extremely frugal budgets: the index updates must be performed within the strict budget of system resources (CPU, memory, storage), and load balancing and relocation of replicas should be performed such that the worst-case on-disk storage overhead of the index is bounded and predictable. Please see my overview post for a high level overview of Cosmos DB. I will be diving in to the subsystems in the coming days.
The resource model

A tenant starts by provisioning a database account using an Azure subscription (you can try it for free at https://azure.microsoft.com/en-us/try/cosmosdb/). The database account manages one or more databases, each of which manages a set of resources: users, permissions, and containers. In Cosmos DB, a container can be projected as a "collection, table, graph" for supporting APIs for "SQL, Table, Gremlin". In addition, a container also manages stored procedures, triggers, user defined functions (UDFs) and attachments.
Each resource is uniquely identified by a stable logical URI and is represented as a JSON document. Developers can interact with resources via HTTP (and over a stateless TCP protocol) using the standard HTTP verbs for CRUD (create, read update, delete), queries, and stored procedures.
All the data within an Azure Cosmos DB container (e.g. collection, table, graph) is horizontally partitioned and Cosmos DB transparently manages those resource partitions behind the scene. Tenants can elastically scale a resource by simply creating new resources which get partitioned (or distributed) across resource partitions automatically.

A resource partition is made highly available by a replica set across Azure regions. I talk about this global distribution next.

Global distribution
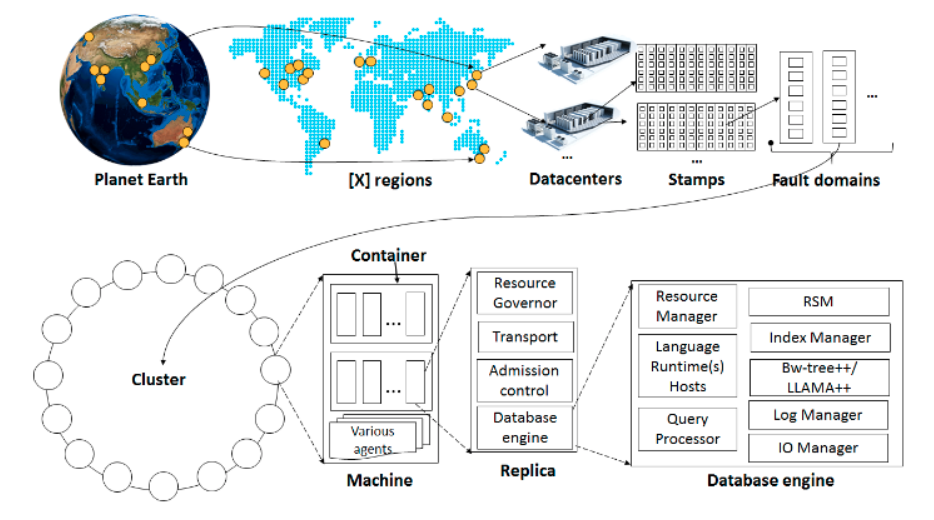
The service is deployed worldwide across multiple Azure regions (50+ of them). Cosmos DB is classified as a foundational service in Azure --which means it is automatically available in every Azure region including public, sovereign, and government clouds. Cosmos DB runs on clusters of machines each with dedicated local SSDs --other storage options for petabyte level data is also configurable.
Each stamp has its own fabric controller. A stamp consists of racks, each of which is built out as a separate fault domain with redundant networking and power. I will summarize the Microsoft fabric paper later.
Each machine hosts replicas corresponding to various resource partitions, which are placed and load balanced across machines in the federation. Each replica hosts an instance of the database engine, which manages the resources (e.g. documents) as well as the associated index. The database engine contains replicated state machine for coordination, the JavaScript language runtime, the query processor, and the storage and indexing subsystems responsible for transactional storage and indexing of documents.
While I won't be able to detail it in this post, Cosmos DB's unique design of resource governance underlies the core of the system: on any single machine there could be hundreds of tenants co-existing, each properly isolated (without any noisy neighbor symptoms) and resource-governed. In addition, Cosmos DB provides a consistent programming model to provision throughput across a heterogeneous set of database operations for each of the tenants at each region at any point in time while maintaining the SLAs.
Schema-agnostic indexing
The schema of a document describes the structure and the type system of the document. In contrast to XML, JSON's type system is simple: it is a strict subset of the type systems of Javascript as well as many other programming languages.The Cosmos DB database engine operates directly at the level of JSON grammar, remaining agnostic to the concept of a document schema and blurring the boundary between the structure and instance values of documents. This, in turn, enables it to automatically index documents without requiring schema or secondary indices as we see below.
Documents as trees
By representing documents as trees, Cosmos DB normalizes both the structure and the instance values across documents into the unifying concept of a dynamically encoded path structure. In this representation, each label in a JSON document (including both the property names and their values) becomes a node of the tree. In other words, the values become first class citizen, the same level as schema labels. Note that the leaves contain actual values and the intermediate nodes the schema information.
The figure above shows the trees created for a document 1 and document 2. The labels are inferred from the document. A (pseudo) root node is created to parent the rest of the (actual) nodes corresponding to the labels in the document underneath. The nested data structures drive the hierarchy in the tree. Intermediate artificial nodes labeled with numeric values (e.g. 0, 1, ...) are employed for representing enumerations, array indices.
Indexing
With automatic indexing, every path in a document tree is indexed (unless the developer configures it to exclude certain path patterns). Therefore, it is important to use a normalized path representation to ensure that the cost to indexing and querying a document with deeply nested structure, say 10 levels, is the same as that of a flat one consisting of key-value pairs of 1 level depth.There are two possible mappings of document and the paths: a forward index mapping, which keeps a map of (document id, path) tuples, as we saw above, and an inverted index mapping, which keeps a map of (path, document id) tuples.
The inverted index provides a very efficient representation for querying. The index tree is a document which is constructed out of the union of all of the trees representing individual documents within the collection. The index tree grows over time as new documents get added or updated to the collection. In contrast to relational database indexing, there is no need for restarting indexing from scratch as new fields are introduced.

Each node of the index tree is an index entry containing the label and position values, called the term, and the ids of the documents, called the postings. The postings in the curly brackets (e.g. {1,2}) in the inverted index figure correspond to the documents (e.g., Document1 and Document2) containing the given label value. An important implication of treating both the schema labels and instance values uniformly is that everything is packed inside a big index. An instance value (still in the leaves) is not repeated, it can be in different roles across documents, with different schema labels, but it is the same value.
The inverted index looks to me as similar to the indexing structures used in a search engine in the information retrieval domain. In a sense, Cosmos DB let's you search your database for anything added to it regardless of its schema structure.
For the normalized path, the service uses a combination of partial (consisting of 3 segments) forward path representation for paths where range support is needed while following partial reverse path representation for paths needing equality (hash) support.
Queries
Developers can query the collections using queries written in SQL and JavaScript. Both SQL and JavaScript queries get translated to an internal intermediate query language (Query IL). The Query IL supports projections, filters, aggregates, sort, flatten operators, expressions (arithmetic, logical, and various data transformations), and user defined functions (UDFs).The query model attempts to strike a balance between functionality, efficiency, and simplicity. The database engine natively compiles and executes the SQL query statements. You can query a collection using the REST APIs or any of the client SDKs. The .NET SDK comes with a LINQ provider. Here is a query playground where you can experiment.
The below figures illustrate point querying and range querying. The inverted index allows the query to identify the documents that match the query predicate quickly. Another important implication of treating both the schema and instance values uniformly in terms of paths is that the inverted index is also a tree. Thus, the index and the results can be serialized to a valid JSON document and returned as documents themselves as they are returned in the tree representation. This enables recursing over these results with additional querying.

For the second query, a range query, GermanTax is a user defined function executed as part of query processing.

Scratching the surface
Here is the summary of the stuff so far. The database engine is designed to be schema-agnostic by representing documents as trees. This enables supporting automatic indexing of documents, serving consistent queries in the face of sustained write volumes under an extremely frugal resource budget in a multitenant environment. (This 2015 talk by Dharma provides a nice summary of these concepts. This page provides code examples for these concepts.)In this post, I only scratched the surface. I haven't started to write about the technical meat of the paper in the logical index organization and the physical index organization sections. These sections introduce a novel logical index layout and a latch-free log-structured storage with blind incremental updates in order to meet the strict requirements of performance (SLA-bounded) and cost effectiveness (in a multitenant environment). Bw-trees introduced by Microsoft Research, a type of B-trees, is employed as part of the physical index organization.
In order to write about those sections more confidently, I will track down the experts here on the logical and physical index organization and will try to get a crash course on these.
MAD questions
1. How do NoSQL and NewSQL indexing methods compare/contrast with those for relational databases?I realized that I am completely ignorant on this topic. But, it also appears that there aren't good explanations on this when I search for it. I will try to find more about this.
2. How do these design decisions fit with the historical trend/direction of database systems?
I found this recent article by Pat Helland very interesting: "Mind Your State for Your State of Mind". So I will plan to summarize it and try to analyze how today's design decisions fit with the historical trends/directions.
"Applications have had an interesting evolution as they have moved into the distributed and scalable world. Similarly, storage and its cousin databases have changed side by side with applications. Many times, the semantics, performance, and failure models of storage and applications do a subtle dance as they change in support of changing business requirements and environmental challenges. Adding scale to the mix has really stirred things up. This article looks at some of these issues and their impact on systems."
3. Can there be a ranking component to the search/querying that enables ranking with respect to user-defined priority? That can be useful for long running or realtime streaming query.





Comments