TLA+ specification of the bounded staleness and strong consistency guarantees

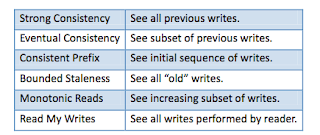
In my previous post , I had presented a TLA+ modeling of distributed data store that provides the consistent prefix property. In this post, I extend this model slightly to build bounded and strong consistency. In fact the strong consistency specification is achieved when we take the Delta on the bounded consistency as 1. The TLA+ (well, PlusCal to be more accurate) code for this model is available at https://www.dropbox.com/s/qvmhhgjf9iycaca/boundedstrongP.tla?dl=0 The system model As in the previous post, we assume there is a write region (with ID=1) and read regions (with IDs 2 through NumRegions). The write region performs the write and copies it to the read regions. There are FIFO communication channels between the write and read regions. WriteRegion == 1 ReadRegions == 2..NumRegions chan = [n \in 1..NumRegions |-> <<>>]; We use D to denote the Delta on the bounded staleness consistency. Bounded staleness ensures that read results are not too stale. ...