Leveraging data and people to accelerate data science (Dr. Laura Haas)
Last week Dr. Laura Haas gave a distinguished speaker series talk at our department. Laura is currently the Dean of the College of Information and Computer Sciences at University of Massachusetts at Amherst. Before that, she was at IBM for many years, and most recently served as the Director of IBM Research’s Accelerated Discovery Lab. Her talk was on her experiences at the Accelerated Discovery Lab, and was titled "Leveraging data and people to accelerate data science"
The lab aimed to manage the technology and data complexity, so that clients can focus on solving their challenges. This job involved providing the clients with:
By providing these services, the lab "accelerated" around 30 projects. The talk highlighted 3 of them:
Food safety is an important problem. Every year, in the USA alone food poisoning affects 1/6th of people, causes $50 million ilnesses, 128K hospitalizations, 3K deaths, and costs 8 billion dollars.
Food poisoning is caused by contaminants/pathogens introduced in the supply-chain. Laura mentioned that the state of the art in food testing was based on developing a suspicion and as a result testing a culture. This means you need to know what you are looking for and when you are looking for it.
Recently DNA sequencing became affordable & fast and enabled the field of metagenomics. Metagenomics is the study of genetic material (across many organisms rather than a single organism) recovered directly from environmental samples. This enabled us to build a database of what is normal for each type of food bacteria pattern. Bacteria are the tiny witnesses to what is going on in the food! They are canary in the coal mine. Change in the bacteria population may point to several pathologies, including lead poisoning. (Weimer et al. IBM Journal of R&D 2016.)
(Murat's inner voice: Umm, good luck blockchainizing that many big files. Ok, it may be possible to store only the hashes for integrity.)
Another big challenge here is that contextual metadata is needed for the samples: when was the sample collected, how, under what conditions, etc.
Data lake helps with the management tasks. A data lake is a data ecosystem to acquire catalogue, govern, find use data in contexts. It includes components such as
Since the data collected involves sensitive information, the employees that have access to the data were made to sign away rights for ensuring privacy of the data. Violating these terms constituted a firable offence. (This doesn't seem to be a rock solid process though. This relies on good intentions of people and the coverage of the monitoring to save the day.)
The lab developed a workbench for metagenomic computational analytics. The multipurpose extensible analysis platform tracks 10K datasets and their derivation, performs automatic parallelization across compute clusters, and provides interactive UI and repeatibility/transparency/accountability. (Edund et.al ibm journal 2016)
For collaboration, email is not sufficient. There are typically around 40K datasets, which ones would you be emailing? Moreover, emailing also doesn't provide enough context about the datasets and metadata.
To support collaboration the lab built a labbook integration hub. (Inner voice: I am relieved it is not Lotus Notes.) The labbook is a giant knowledge graph that is annotatable, searchable, and is interfaced with many tools, including Python, Notebooks, etc. Sort of like Jupiter Notebooks on steroids?
As for the future, Laura mentioned that being very broad does not work/scale well for a data science organization, since it is hard to please every one. She said that the accelerated discovery lab will focus on metagenomic and materials science to stay more relevant.
1. At the question answer time for the talk, I asked Laura about IBM's recent push for blockchains in food safety and supply-chain applications. Given that the talk outlined many hard challenges for food safety supply chains, I wanted to learn about her views on what roles blockchains can play here. Laura said that in food supply-chains there were some problems with faked provenance of sources and blockchains may help address that issue. She also said that she won't comment if blockchain is the right way to address it, since it is not her field of expertise.
2. My question was prompted by IBM's recent tweet of this whitepaper which I found to be overly exuberant about the role blockchains can play in the supply-chain problems.(https://twitter.com/Prof_DavidBader/status/964223296005967878) Below is the Twitter exchange ensued after I took issue with the report. Notice how mature @IBMServices account is about this? They pressed on to learn more about the criticism, which is a good indicator of intellectual honesty. (I wish I could have been a bit more restrained.)
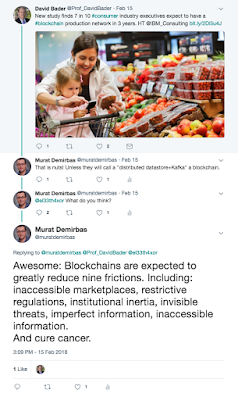

I like to write a post about the use of blockchains in supply-chains. Granted I don't know much about the domain, but when did that ever stop me?
3. This is a little unrelated, but was there any application of formal methods in the supply-chain problem before?
4. The talk also mentioned a bit about applying datascience to measure contributions of datascience in these projects. This is done via collaboration trace analysis: who is working with who, how much, and in what contexts? A noteworthy finding was the "emergence of new vocabulary right before a discovery events". This rings very familiar in our research group meeting discussions. When we observe an interesting new phenomenon/perspective, we are forced to give it a made-up name, which sounds clumsy at first. When we keep referring to this given name, we know there is something interesting coming up from that front.
Accelerated Discovery Lab
The mission of the lab was to "help people get insight from data -- quickly".The lab aimed to manage the technology and data complexity, so that clients can focus on solving their challenges. This job involved providing the clients with:
- expertise: math, ml, computing
- environment: hosted big data platforms
- data: curated & governed data sets to provide context
- analytics: rich collection of analytics and tools.
By providing these services, the lab "accelerated" around 30 projects. The talk highlighted 3 of them:
- Working with CRM and social media information, which involved managing complex data.
- Working with a major seed company, which involved analyzing satellite imaging, and deciding what/how to plant, and choosing the workflows that provide auditability, quality, accuracy.
- Working with a drug company, which involved "big" collaboration across diverse teams and organizations.
The Food Safety Project
The bulk of the talk focused on the food-safety case-study application that the lab worked on.Food safety is an important problem. Every year, in the USA alone food poisoning affects 1/6th of people, causes $50 million ilnesses, 128K hospitalizations, 3K deaths, and costs 8 billion dollars.
Food poisoning is caused by contaminants/pathogens introduced in the supply-chain. Laura mentioned that the state of the art in food testing was based on developing a suspicion and as a result testing a culture. This means you need to know what you are looking for and when you are looking for it.
Recently DNA sequencing became affordable & fast and enabled the field of metagenomics. Metagenomics is the study of genetic material (across many organisms rather than a single organism) recovered directly from environmental samples. This enabled us to build a database of what is normal for each type of food bacteria pattern. Bacteria are the tiny witnesses to what is going on in the food! They are canary in the coal mine. Change in the bacteria population may point to several pathologies, including lead poisoning. (Weimer et al. IBM Journal of R&D 2016.)
The big data challenge in food safety
If you have a safe sample for metagenomics, you can expect to see 2400 microbial species. As a result, one metagenomics file is 250 GB! And 50 metagenomics samples result in 149 workflows invoked 42K times producing 271K files and 116K graphs.(Murat's inner voice: Umm, good luck blockchainizing that many big files. Ok, it may be possible to store only the hashes for integrity.)
Another big challenge here is that contextual metadata is needed for the samples: when was the sample collected, how, under what conditions, etc.
Data lake helps with the management tasks. A data lake is a data ecosystem to acquire catalogue, govern, find use data in contexts. It includes components such as
- schema: fields, columns, types, keys
- semantics: lineage, ontology
- governance: owner, risk, guidelines, maintenance
- collaboration: users, applications, notebooks
Since the data collected involves sensitive information, the employees that have access to the data were made to sign away rights for ensuring privacy of the data. Violating these terms constituted a firable offence. (This doesn't seem to be a rock solid process though. This relies on good intentions of people and the coverage of the monitoring to save the day.)
The big analytics challenge in food safety
Mapping a 60Gb raw test-sample data file against a 100Gb references database may take hours to days! To make things work data and references files keep getting updated.The lab developed a workbench for metagenomic computational analytics. The multipurpose extensible analysis platform tracks 10K datasets and their derivation, performs automatic parallelization across compute clusters, and provides interactive UI and repeatibility/transparency/accountability. (Edund et.al ibm journal 2016)
The big collaboration challenge in food safety
4 organizations worked together on the food safety project: IBM, mars petfood company (pet-food chains were the most susceptible to contamination), UC Davis, and Bio-Rad labs. Later Cornell also joined. The participants spanned across US, UK, and China. The participants didn't talk the same language: the disciplines spanned across business, biology, bioinformatics, physics, chemistry, cs, ml, stat, math, and operations research.For collaboration, email is not sufficient. There are typically around 40K datasets, which ones would you be emailing? Moreover, emailing also doesn't provide enough context about the datasets and metadata.
To support collaboration the lab built a labbook integration hub. (Inner voice: I am relieved it is not Lotus Notes.) The labbook is a giant knowledge graph that is annotatable, searchable, and is interfaced with many tools, including Python, Notebooks, etc. Sort of like Jupiter Notebooks on steroids?
Things learned
Laura finished with some lessons learned. Her take on this was: Data science needs to be holistic, incorporating all these three: people, data, analytics.- People: interdisciplinary hard, social practices/tools can help
- Data: data governance is hard, it needs policies, tools
- Analytics: many heterogenous set of tools need to be integrated for handling uncertainty
As for the future, Laura mentioned that being very broad does not work/scale well for a data science organization, since it is hard to please every one. She said that the accelerated discovery lab will focus on metagenomic and materials science to stay more relevant.
MAD questions
(This section is here due to my New Year's resolution.)1. At the question answer time for the talk, I asked Laura about IBM's recent push for blockchains in food safety and supply-chain applications. Given that the talk outlined many hard challenges for food safety supply chains, I wanted to learn about her views on what roles blockchains can play here. Laura said that in food supply-chains there were some problems with faked provenance of sources and blockchains may help address that issue. She also said that she won't comment if blockchain is the right way to address it, since it is not her field of expertise.
2. My question was prompted by IBM's recent tweet of this whitepaper which I found to be overly exuberant about the role blockchains can play in the supply-chain problems.(https://twitter.com/Prof_DavidBader/status/964223296005967878) Below is the Twitter exchange ensued after I took issue with the report. Notice how mature @IBMServices account is about this? They pressed on to learn more about the criticism, which is a good indicator of intellectual honesty. (I wish I could have been a bit more restrained.)


I like to write a post about the use of blockchains in supply-chains. Granted I don't know much about the domain, but when did that ever stop me?
3. This is a little unrelated, but was there any application of formal methods in the supply-chain problem before?
4. The talk also mentioned a bit about applying datascience to measure contributions of datascience in these projects. This is done via collaboration trace analysis: who is working with who, how much, and in what contexts? A noteworthy finding was the "emergence of new vocabulary right before a discovery events". This rings very familiar in our research group meeting discussions. When we observe an interesting new phenomenon/perspective, we are forced to give it a made-up name, which sounds clumsy at first. When we keep referring to this given name, we know there is something interesting coming up from that front.



Comments