Paper summary. Real-Time Machine Learning: The Missing Pieces
This paper, dated March 11, 2017 on arxiv, is from UB Berkeley. Here is Prof. Michael Jordan's Strata Hadoop conference talk on this.
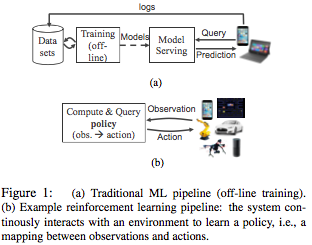
The paper first motivates the need for real-time machine learning. For this it mentions in-situ reinforcement learning (RL) that closes the loop by taking actions that affect the sensed environment. (The second paragraph mentions that such RL can be trained more feasibly by using simulated/virtual environments: by first trying multiple actions [potentially in parallel] to see their affect in simulation before interacting with the real world. Again this requires real-time performance as the simulation should be performed faster than real-time interaction.)
Based on this application scenario, here are their desired requirement from the ML platform.
R1: low latency
R2: high throughput
R3: dynamic task creation (RL primitives such as Monte Carlo tree search may generate new tasks during execution)
R4: heterogeneous tasks (tasks would have widely different execution times and resource requirements)
R5: arbitrary dataflow dependencies (BSP doesn't cut it)
R6: transparent fault-tolerance
R7: debuggability and profiling

Two principal architectural features are a centralized control plane and a hybrid scheduler. The centralized control state is held by Redis, a replicated key-value store. It looks like the control state does not have any control logic in it, it is just passive storage. (So TensorFlow's variables also qualify as control state.) The hybrid scheduler idea aims to help with providing low-latency. Workers submit tasks to their local schedulers which decide to either assign the tasks to other workers on the same physical node or to “spill over” the tasks to a global scheduler. Global schedulers can then assign tasks to local schedulers based on global information about resource availability. Neither the logically centralized control state nor the two-level hierarchy scheduling are new innovative concepts.
The tasks creation is left totally to the application developer. Any task can create new tasks without blocking on their completion, but this creates a dependency from the caller to the callee. Moreover, Ray uses the dataflow execution model in which tasks become available for execution if and only if their dependencies have finished executing. The combination of this unrestrained task creation with hybrid scheduling provides a lot of rope to the developer to hang himself.
Tasks are called with split-phase asynchronous execution model. When you call a task, the task returns "future", which just denotes acknowledgement, but the task will later call you back with the result when its computation is completed. The caller may potentially call "get" on the future to block until the callee finishes execution. Ray also has a "wait" primitive to time out from waiting on straggler tasks. Again it is the developer's responsibility to figure out how to use this correctly.
While Ray aims real-time machine learning, it doesn't have a way for shedding load. To provide load shedding support, it is possible to adopt the SEDA architecture, so the system does not grind to a halt when it is presented with too many tasks at once.
The paper first motivates the need for real-time machine learning. For this it mentions in-situ reinforcement learning (RL) that closes the loop by taking actions that affect the sensed environment. (The second paragraph mentions that such RL can be trained more feasibly by using simulated/virtual environments: by first trying multiple actions [potentially in parallel] to see their affect in simulation before interacting with the real world. Again this requires real-time performance as the simulation should be performed faster than real-time interaction.)

Based on this application scenario, here are their desired requirement from the ML platform.
R1: low latency
R2: high throughput
R3: dynamic task creation (RL primitives such as Monte Carlo tree search may generate new tasks during execution)
R4: heterogeneous tasks (tasks would have widely different execution times and resource requirements)
R5: arbitrary dataflow dependencies (BSP doesn't cut it)
R6: transparent fault-tolerance
R7: debuggability and profiling
The platform architecture
The paper does not give a name to the platform, but the talk calls it Ray. Ray allows arbitrary functions to be specified as remotely executable tasks, with dataflow dependencies between them. Ray uses imperative programming and does not support symbolic computation graphs, as far as I can see. The talk mentions that programming is done in Python. So, at this point Ray is more like a set of Python libraries paired with Redis database for keeping control state and with Spark RDD support for maintaining object-store as shared memory.
Two principal architectural features are a centralized control plane and a hybrid scheduler. The centralized control state is held by Redis, a replicated key-value store. It looks like the control state does not have any control logic in it, it is just passive storage. (So TensorFlow's variables also qualify as control state.) The hybrid scheduler idea aims to help with providing low-latency. Workers submit tasks to their local schedulers which decide to either assign the tasks to other workers on the same physical node or to “spill over” the tasks to a global scheduler. Global schedulers can then assign tasks to local schedulers based on global information about resource availability. Neither the logically centralized control state nor the two-level hierarchy scheduling are new innovative concepts.
The tasks creation is left totally to the application developer. Any task can create new tasks without blocking on their completion, but this creates a dependency from the caller to the callee. Moreover, Ray uses the dataflow execution model in which tasks become available for execution if and only if their dependencies have finished executing. The combination of this unrestrained task creation with hybrid scheduling provides a lot of rope to the developer to hang himself.
Tasks are called with split-phase asynchronous execution model. When you call a task, the task returns "future", which just denotes acknowledgement, but the task will later call you back with the result when its computation is completed. The caller may potentially call "get" on the future to block until the callee finishes execution. Ray also has a "wait" primitive to time out from waiting on straggler tasks. Again it is the developer's responsibility to figure out how to use this correctly.
Conclusions
I think the platform is weak on "ease of use". Ray is so minimal that it is unclear if we couldn't have gotten the same level of support from using a systems programming language with concurrency primitives and thread safety, such as Rust. Rust uses the actor model and is very suitable for building a dataflow execution application, as has been demonstrated by rewriting Naiad on Rust recently.While Ray aims real-time machine learning, it doesn't have a way for shedding load. To provide load shedding support, it is possible to adopt the SEDA architecture, so the system does not grind to a halt when it is presented with too many tasks at once.





Comments