OpenCL
Open Computing Language (OpenCL) is a framework for writing programs that execute across heterogeneous platforms consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs), or field-programmable gate arrays (FPGAs). Heterogeneous computing refers to systems that use more than one kind of processor or cores for high performance or energy efficiency.
OpenCL views a computing system as consisting of a number of compute devices (GPUs, CPUs, FPGAs) attached to a host processor (a CPU). It defines a C-like language for writing programs. Functions executed on an OpenCL device are called /kernels/. A single compute device typically consists of several compute units, which in turn comprise multiple processing elements (PEs). A single kernel execution can run on all or many of the PEs in parallel.
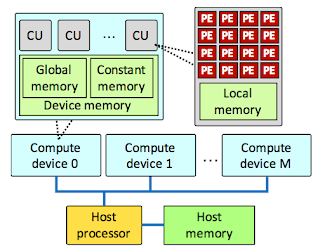
In addition to its C-like programming language, OpenCL defines an API that allows programs running on the host to launch kernels on the compute devices and manage device memory. Programs in the OpenCL language are intended to be compiled at run-time, so that OpenCL-using applications are portable between implementations for various host devices.
OpenCL is an open standard maintained by the non-profit technology consortium Khronos Group. Conformant implementations are available from Altera, AMD, Apple, ARM, Creative, IBM, Imagination, Intel, NVIDIA, Qualcomm, Samsung, Vivante, Xilinx, and ZiiLABS. Although OpenCL provides an alternative to CUDA, it has some support from NVDIA.
OpenCL is supported by Android, FreeBSD, Arch Linux, Linux, macOS, Windows operating systems.
A 2015 paper, Bridging OpenCL and CUDA: a comparative analysis and translation, also provides CUDA-OpenCL translation as well as OpenCL-CUDA translation.
These translators, however, do not provide industry-grade and ruggedized implementations.

Recently an OpenCL port of Caffee was made available. This Caffe port was shown/evaluated for AMD chipsets, but it should also apply for ARM platforms that support OpenCL.
OpenCL views a computing system as consisting of a number of compute devices (GPUs, CPUs, FPGAs) attached to a host processor (a CPU). It defines a C-like language for writing programs. Functions executed on an OpenCL device are called /kernels/. A single compute device typically consists of several compute units, which in turn comprise multiple processing elements (PEs). A single kernel execution can run on all or many of the PEs in parallel.

In addition to its C-like programming language, OpenCL defines an API that allows programs running on the host to launch kernels on the compute devices and manage device memory. Programs in the OpenCL language are intended to be compiled at run-time, so that OpenCL-using applications are portable between implementations for various host devices.
OpenCL is an open standard maintained by the non-profit technology consortium Khronos Group. Conformant implementations are available from Altera, AMD, Apple, ARM, Creative, IBM, Imagination, Intel, NVIDIA, Qualcomm, Samsung, Vivante, Xilinx, and ZiiLABS. Although OpenCL provides an alternative to CUDA, it has some support from NVDIA.
OpenCL is supported by Android, FreeBSD, Arch Linux, Linux, macOS, Windows operating systems.
CUDA to OpenCL translators
A prototype implementation exists for CUDA to OpenCL translator.A 2015 paper, Bridging OpenCL and CUDA: a comparative analysis and translation, also provides CUDA-OpenCL translation as well as OpenCL-CUDA translation.
These translators, however, do not provide industry-grade and ruggedized implementations.
OpenCL for ML
OpenCL support is still underwhelming for deep learning, but it is getting better.
Recently an OpenCL port of Caffee was made available. This Caffe port was shown/evaluated for AMD chipsets, but it should also apply for ARM platforms that support OpenCL.





Comments