Paper summary. Untangling Blockchain: A Data Processing View of Blockchain Systems
This is a recent paper submitted to arxiv (Aug 17, 2017). The paper presents a hype-free, very accessible, yet technical survey on blockchain. It takes a data-processing centric view of blockchain technology, treating concurrency issues and efficiency of consensus as first class citizens in blockchain design. Approaching from that perspective, the paper tries to forge a connection with blockchain technologies and distributed transaction processing systems. I think this perspective is promising for grounding the blockchain research better. When we connect a new area to an area with a large literature, we have opportunities to compare/contrast and perform efficient OODA loops.
Thanks to this paper, I am finally getting excited about blockchains. I had a huge prejudice about blockchains based on the Proof-of-Work approach being used in BitCoin. Nick Szabo tried to defend this huge inefficiency, citing that it is necessary for attestation/decentralized/etc, but that is a false dichotomy. There are many efficient ways to design blockchains and still provide decentralization and attestation guarantees. And the paper provides an exhaustive survey of blockchain design approaches.
In my summary below, I use many sentences (sometimes paragraphs) directly lifted off from the paper. The paper is easily accessible and well written, and worth reading if you like to learn about blockchains.
Blockchains have many applications in business, such as security trading and settlement, asset and finance management banking, and insurance. Currently these applications are handled by systems built on MySQL and Oracle and by trusted companies/parties with whole bunch of lawyers/clerks/etc. Blockchain can disrupt this status quo because it reduces infrastructure and human costs. Blockchain's immutability, transparency, and inherent security help reduce human errors/malice and the need for manual intervention due to conflicting data. The paper says: "Goldman Sachs estimated 6 billion saving in current capital market, and J.P. Morgan forecast that blockchains will start to replace currently redundant infrastructure by 2020."
Oops, I forgot to mention Bitcoin. Bitcoin is also one of the applications of blockchains, namely a digital/crypto-currency application. Cryptocurrency is currently the most famous application of blockchains, but as the paper covers smartcontracts, you can see that those applications will dwarf anything we have seen so far.
Public blockchain: Bitcoin uses proof-of-work (PoW) for consensus: only a miner which has successfully solved a computationally hard puzzle (finding the right nonce for the block header) can append to the blockchain. It is still possible that two blocks are appended at the same time, creating a fork in the blockchain. Bitcoin resolves this by only considering a block as confirmed after it is followed by a number of blocks (typically six blocks). PoW works well in the public settings because it guards against Sybil attacks, however, since it is non-deterministic and computationally expensive, it is unsuitable for applications such as banking and finance which must handle large volumes of transactions in a deterministic manner. (Bitcoin supports 7 transactions per second!)
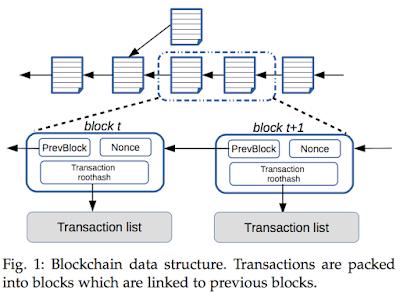
Private blockchain: Since node identities are known in the private settings, most blockchains adopt one of the protocols from the vast literature on distributed consensus. Hyperledger v0.6.0 uses PBFT, a byzantine tolerant Paxos, while some other private chains even use plain Paxos. (Hyperledger v1.0.0-rc1 adopts a no-Byzantine consensus protocol based on Kafka.)
However, even with PBFT (or XFT) scalability is a problem. Those Paxos protocols will not be able to scale to tens of nodes, let alone hundreds. An open research question is how can you have big-Paxos? (The federated consensus approach mentioned below is a promising approach to solve this problem.)
Distributed ledger: In blockchains, the ledger is replicated over all the nodes as an append-only data structure. A blockchain starts with some initial states, and the ledger records entire history of update operations made to the states. (This reminds me of Tango and particularly the followup vCorfu paper. The ideas explored there can be used for efficiently maintaining multiple streams in the same log so that reading the whole chain is not needed for materializing the updates at the nodes.)
Cryptography: This is used for ensuring the integrity of the ledgers, for making sure there is no tampering of the blockchain data. The global states are protected by a hash (Merkle) tree whose root hash is stored in a block. The block history is also protected by linking the blocks through a chain of cryptographic hash pointers: the content of block number n+1 contains the hash of block number n. This way, any modification in block n immediately invalidates all the subsequent blocks.
Smart Contracts: A smart contract refers to the computation executed when a transaction is performed. At the trivial end of the spectrum, Bitcoin nodes implement a simple replicated state machine model which moves coins from one address to another. At the other extreme, Ethereum smart contracts can specify arbitrary computations and comes with its own virtual machine for executing Ethereum bytecodes. Similarly, Hyperledger employs Docker containers to execute its contracts written in any language. Smart contracts have many emerging business applications, but this makes software bugs very critical. In the DAO attack, the attacker stole $50M worth of asset exploiting a bug.

Proof of work: All PoW protocols require miners to find solutions to cryptographic puzzles based on cryptographic hashes. How fast a block is created is dependent on how hard the puzzle is. The puzzle cannot be arbitrary east because it leads to unnecessary forks in the blockchain. Forks not only lead to wastage of resources but have security implication since they make it possible to double spend. Ethereum, another PoW-based blockchain, adopts GHOST protocol which helps bring down block generation time to tens of seconds without compromising much security. In GHOST, the blockchain is allowed to have branches as long as the branches do not contain conflicting transactions.
Proof of Stake: To alleviate huge cost of PoW, PoS maintains a single branch but changes the puzzle's difficulty to be inversely proportional to the miner's stake in the network. A stake is essentially a locked account with a certain balance representing the miner's commitment to keep the network healthy.
Paxos protocols: PoW suffers from non-finality, that is a block appended to a blockchain is not confirmed until it is extended by many other blocks. PBFT protocol is deterministic. Implemented in the earlier version of Hyperledger (v0.6), the protocol ensures that once a block is appended, it is final and cannot be replaced or modified. It incurs O(N^2) network messages for each round of agreement where N is the number of nodes in the network. (This is because in contrast to classical Paxos, where every participant talks only with the leader, in PBFT, every participant talks to every other participant as well.) The paper reports that PBFT scales poorly and collapses even before reaching the network limit. Zyzzyva optimizes for normal cases (when there are no failures) via speculative execution. XFT, assumes a network less hostile than purely Byzantine, and demonstrates better performance by reducing the number of network messages.
Federated: To overcome the scalability woes with PBFT, Ripple adopts an approach that partitions the network into smaller groups called federates. Each federate runs a local consensus protocol among its members, and the local agreements are then propagated to the entire network via nodes lying in the intersections of the federates. Ripple’s safety conditions are that there is a large majority of honest nodes in every federate, and that the intersection of any two federates contain at least one honest node. Ripple assumes federates are pre-defined and their safety conditions can be enforced by a network administrator. In a decentralized environment where node identities are unknown, such assumptions do not hold. Byzcoin and Elastico propose novel, two-phase protocols that combine PoW and PBFT. In the first phase, PoW is used to form a consensus group. Byzcoin implements this by having a sliding window over the blockchain and selecting the miners of the blocks within the window. Elastico groups nodes by their identities that change every epoch. In particular, a node identity is its solution to a cryptographic puzzle. In the second phase, the selected nodes perform PBFT to determine the next block. The end result is faster block confirmation time at a scale much greater than traditional PBFT (over 1000 nodes).
Nonbyzantine: The latest release of Hyperledger (v1.0) outsources the consensus component to Kafka. More specifically, transactions are sent to a centralized Kafka service which orders them into a stream of events. Every node subscribes to the same Kafka stream and therefore is notified of new transactions in the same order as they are published.

I love that Blockchains brings new constraints and requirements to the consensus problem. In Blockchains, the participants can now be Byzantine, motivated by financial gains. And it is not sufficient to limit the consensus participants to be 3 nodes or 5 nodes, which was enough for tolerating crashes and ensuring persistency of the data. In Blockchains, for reasons of attestability and tolerating colluding groups of Byzantine participants, it is preferred to keep the participants at 100s. Thus the problem becomes: How do you design byzantine tolerant consensus algorithm that scales to 100s or 1000s of participants?
I love when applications push us to invent new distributed algorithms.

The paper then presents a comprehensive evaluation of Ethereum, Parity and Hyperledger. The comparison against H-Store presented demonstrates that blockchains perform poorly at data processing tasks currently being handled by database systems. Although databases are designed without security and tolerance to Byzantine failures, the gap remains too big for blockchains to be disruptive to incumbent database systems.

The main findings are:
Thanks to this paper, I am finally getting excited about blockchains. I had a huge prejudice about blockchains based on the Proof-of-Work approach being used in BitCoin. Nick Szabo tried to defend this huge inefficiency, citing that it is necessary for attestation/decentralized/etc, but that is a false dichotomy. There are many efficient ways to design blockchains and still provide decentralization and attestation guarantees. And the paper provides an exhaustive survey of blockchain design approaches.
In my summary below, I use many sentences (sometimes paragraphs) directly lifted off from the paper. The paper is easily accessible and well written, and worth reading if you like to learn about blockchains.
Blockchain basics
Blockchain is a log of ordered blocks, each containing multiple transactions. In the database context, blockchain can be viewed as a solution to distributed transaction management: nodes keep replicas of the data and agree on an execution order of transactions. Distributed transaction processing systems often deal with concurrency control via 2-phase commit. However, in order to tolerate Byzantine behavior, the overhead of concurrency control becomes higher in blockchains.Blockchains have many applications in business, such as security trading and settlement, asset and finance management banking, and insurance. Currently these applications are handled by systems built on MySQL and Oracle and by trusted companies/parties with whole bunch of lawyers/clerks/etc. Blockchain can disrupt this status quo because it reduces infrastructure and human costs. Blockchain's immutability, transparency, and inherent security help reduce human errors/malice and the need for manual intervention due to conflicting data. The paper says: "Goldman Sachs estimated 6 billion saving in current capital market, and J.P. Morgan forecast that blockchains will start to replace currently redundant infrastructure by 2020."
Oops, I forgot to mention Bitcoin. Bitcoin is also one of the applications of blockchains, namely a digital/crypto-currency application. Cryptocurrency is currently the most famous application of blockchains, but as the paper covers smartcontracts, you can see that those applications will dwarf anything we have seen so far.
Private vs Public blockchains
In public blockchains, any node can join/leave the system, thus the blockchain is fully decentralized, resembling a peer-to-peer system. In private blockchains, the blockchain enforces strict membership via access-control and authentication.Public blockchain: Bitcoin uses proof-of-work (PoW) for consensus: only a miner which has successfully solved a computationally hard puzzle (finding the right nonce for the block header) can append to the blockchain. It is still possible that two blocks are appended at the same time, creating a fork in the blockchain. Bitcoin resolves this by only considering a block as confirmed after it is followed by a number of blocks (typically six blocks). PoW works well in the public settings because it guards against Sybil attacks, however, since it is non-deterministic and computationally expensive, it is unsuitable for applications such as banking and finance which must handle large volumes of transactions in a deterministic manner. (Bitcoin supports 7 transactions per second!)

Private blockchain: Since node identities are known in the private settings, most blockchains adopt one of the protocols from the vast literature on distributed consensus. Hyperledger v0.6.0 uses PBFT, a byzantine tolerant Paxos, while some other private chains even use plain Paxos. (Hyperledger v1.0.0-rc1 adopts a no-Byzantine consensus protocol based on Kafka.)
However, even with PBFT (or XFT) scalability is a problem. Those Paxos protocols will not be able to scale to tens of nodes, let alone hundreds. An open research question is how can you have big-Paxos? (The federated consensus approach mentioned below is a promising approach to solve this problem.)
What makes Blockchains tick?
The paper studies blockchain technology under four dimensions: distributed ledger, cryptography, consensus protocol and smartcontracts.Distributed ledger: In blockchains, the ledger is replicated over all the nodes as an append-only data structure. A blockchain starts with some initial states, and the ledger records entire history of update operations made to the states. (This reminds me of Tango and particularly the followup vCorfu paper. The ideas explored there can be used for efficiently maintaining multiple streams in the same log so that reading the whole chain is not needed for materializing the updates at the nodes.)
Cryptography: This is used for ensuring the integrity of the ledgers, for making sure there is no tampering of the blockchain data. The global states are protected by a hash (Merkle) tree whose root hash is stored in a block. The block history is also protected by linking the blocks through a chain of cryptographic hash pointers: the content of block number n+1 contains the hash of block number n. This way, any modification in block n immediately invalidates all the subsequent blocks.
Smart Contracts: A smart contract refers to the computation executed when a transaction is performed. At the trivial end of the spectrum, Bitcoin nodes implement a simple replicated state machine model which moves coins from one address to another. At the other extreme, Ethereum smart contracts can specify arbitrary computations and comes with its own virtual machine for executing Ethereum bytecodes. Similarly, Hyperledger employs Docker containers to execute its contracts written in any language. Smart contracts have many emerging business applications, but this makes software bugs very critical. In the DAO attack, the attacker stole $50M worth of asset exploiting a bug.

Consensus:
Since I am partial to distributed consensus, I am reserving a separate section to the use of consensus in blockchains.Proof of work: All PoW protocols require miners to find solutions to cryptographic puzzles based on cryptographic hashes. How fast a block is created is dependent on how hard the puzzle is. The puzzle cannot be arbitrary east because it leads to unnecessary forks in the blockchain. Forks not only lead to wastage of resources but have security implication since they make it possible to double spend. Ethereum, another PoW-based blockchain, adopts GHOST protocol which helps bring down block generation time to tens of seconds without compromising much security. In GHOST, the blockchain is allowed to have branches as long as the branches do not contain conflicting transactions.
Proof of Stake: To alleviate huge cost of PoW, PoS maintains a single branch but changes the puzzle's difficulty to be inversely proportional to the miner's stake in the network. A stake is essentially a locked account with a certain balance representing the miner's commitment to keep the network healthy.
Paxos protocols: PoW suffers from non-finality, that is a block appended to a blockchain is not confirmed until it is extended by many other blocks. PBFT protocol is deterministic. Implemented in the earlier version of Hyperledger (v0.6), the protocol ensures that once a block is appended, it is final and cannot be replaced or modified. It incurs O(N^2) network messages for each round of agreement where N is the number of nodes in the network. (This is because in contrast to classical Paxos, where every participant talks only with the leader, in PBFT, every participant talks to every other participant as well.) The paper reports that PBFT scales poorly and collapses even before reaching the network limit. Zyzzyva optimizes for normal cases (when there are no failures) via speculative execution. XFT, assumes a network less hostile than purely Byzantine, and demonstrates better performance by reducing the number of network messages.
Federated: To overcome the scalability woes with PBFT, Ripple adopts an approach that partitions the network into smaller groups called federates. Each federate runs a local consensus protocol among its members, and the local agreements are then propagated to the entire network via nodes lying in the intersections of the federates. Ripple’s safety conditions are that there is a large majority of honest nodes in every federate, and that the intersection of any two federates contain at least one honest node. Ripple assumes federates are pre-defined and their safety conditions can be enforced by a network administrator. In a decentralized environment where node identities are unknown, such assumptions do not hold. Byzcoin and Elastico propose novel, two-phase protocols that combine PoW and PBFT. In the first phase, PoW is used to form a consensus group. Byzcoin implements this by having a sliding window over the blockchain and selecting the miners of the blocks within the window. Elastico groups nodes by their identities that change every epoch. In particular, a node identity is its solution to a cryptographic puzzle. In the second phase, the selected nodes perform PBFT to determine the next block. The end result is faster block confirmation time at a scale much greater than traditional PBFT (over 1000 nodes).
Nonbyzantine: The latest release of Hyperledger (v1.0) outsources the consensus component to Kafka. More specifically, transactions are sent to a centralized Kafka service which orders them into a stream of events. Every node subscribes to the same Kafka stream and therefore is notified of new transactions in the same order as they are published.

I love that Blockchains brings new constraints and requirements to the consensus problem. In Blockchains, the participants can now be Byzantine, motivated by financial gains. And it is not sufficient to limit the consensus participants to be 3 nodes or 5 nodes, which was enough for tolerating crashes and ensuring persistency of the data. In Blockchains, for reasons of attestability and tolerating colluding groups of Byzantine participants, it is preferred to keep the participants at 100s. Thus the problem becomes: How do you design byzantine tolerant consensus algorithm that scales to 100s or 1000s of participants?
I love when applications push us to invent new distributed algorithms.
Blockbench and evaluation
The paper introduces a benchmarking framework, BLOCKBENCH, that is designed for understanding performance of private blockchains against data processing workloads. BLOCKBENCH is open source and contains YCSB and SmallBank data processing workloads as well as some popular Ethereum contracts.
The paper then presents a comprehensive evaluation of Ethereum, Parity and Hyperledger. The comparison against H-Store presented demonstrates that blockchains perform poorly at data processing tasks currently being handled by database systems. Although databases are designed without security and tolerance to Byzantine failures, the gap remains too big for blockchains to be disruptive to incumbent database systems.

The main findings are:
- Hyperledger performs consistently better than Ethereum and Parity across the benchmarks. But it fails to scale up to more than 16 nodes.
- Ethereum and Parity are more resilient to node failures, but they are vulnerable to security attacks that forks the blockchain.
- The main bottlenecks in Hyperledger and Ethereum are the consensus protocols, but for Parity the bottleneck is caused by transaction signing.
- Ethereum and Parity incur large overheads in terms of memory and disk usage. Their execution engine is also less efficient than that of Hyperledger.
- Hyperledger’s data model is low level, but its flexibility enables customized optimization for analytical queries.





Comments
Also, I'm interested in the topic of open membership BFT algorithm, do we have such algorithms in reality? (Of course PoW/PoS/... whatever they do, I'm just interested in algorithms without mining)