Paper summary. Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds
This paper appeared in NSDI'17 and is authored by Kevin Hsieh, Aaron Harlap, Nandita Vijaykumar, Dimitris Konomis, Gregory R. Ganger, Phillip B. Gibbons, and Onur Mutlu.
Google's Federated Learning also considered similar motivations, and set out to reduce WAN communication. It worked as follows: 1) smartphones are sent the model by the master/datacenter parameter-server, 2) smartphones compute an updated model based on their local data over some number of iterations, 3) the updated models are sent from the smartphones to the datacenter parameter-server, 4) the datacenter parameter-server aggregates these models (by averaging) to construct the new global model, and 5) Repeat.
The Gaia paper does not cite Federated Learning paper, because they are likely submitted around the same time. There are many parallels between Gaia's approach and that of Federated Learning. Both are based on the parameter-server model, and both prescribe updating the model parameters in a relaxed/stale/approximate synchronous parallel fashion: several iterations are run in-situ before updating the "master" parameter-server. The difference is for Federated Learning there is a "master" parameter-server in the datacenter, whereas Gaia takes a peer-to-peer approach where each datacenter has a parameter-server, and updating the "master" datacenter means synchronizing the parameter-servers across the datacenters.
ASP builds heavily on the Stale Synchronous Parallelism (SSP) idea for parameter-server ML systems. While SSP bounds how stale (i.e., old) a parameter can be, ASP bounds how inaccurate a parameter can be, in comparison to the most up-to-date value.
ASP allows the ML programmer to specify the function and the threshold to determine the significance of updates for each ML algorithm. The significance threshold has 2 parts: a hard and a soft threshold. The purpose of the hard threshold is to guarantee ML algorithm convergence, while that of soft threshold is to use underutilized WAN bandwidth to speed up convergence. In other words, the soft threshold provides an opportunistic synchronization threshold.
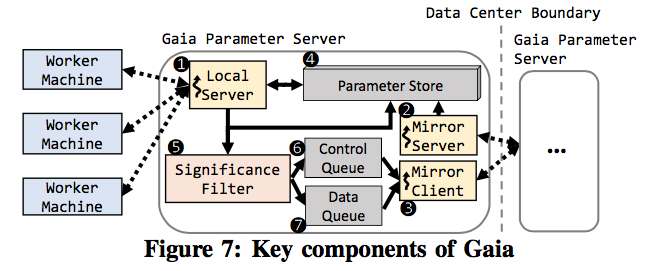
 Figure 4 shows the overview of Gaia. In Gaia, each data center has some worker machines and parameter servers. Each worker machine works on a shard of the input data stored in its data center to achieve data parallelism. The parameter servers in each data center collectively maintain a version of the global model copy, and each parameter server handles a shard of this global model copy. A worker machine only READs and UPDATEs the global model copy in its data center. To reduce the communication overhead over WANs, ASP is used between parameter-servers across different data centers. Below are the 3 components of ASP.
Figure 4 shows the overview of Gaia. In Gaia, each data center has some worker machines and parameter servers. Each worker machine works on a shard of the input data stored in its data center to achieve data parallelism. The parameter servers in each data center collectively maintain a version of the global model copy, and each parameter server handles a shard of this global model copy. A worker machine only READs and UPDATEs the global model copy in its data center. To reduce the communication overhead over WANs, ASP is used between parameter-servers across different data centers. Below are the 3 components of ASP.
The significance filter. ASP takes 2 inputs from user: (1) a significance function and (2) an initial significance threshold. A parameter server aggregates updates from the local worker machines and shares the aggregated updates with other datacenters when the aggregate becomes significant. To facilitate convergence to the optimal point, ASP automatically reduces the significance threshold over time: if the original threshold is v, then the threshold at iteration t of the ML algorithm is $\frac{v}{\sqrt{t}}$.

ASP selective barrier. When a parameter-server receives the significant updates at a rate that is higher than the WAN bandwidth can support, instead of sending updates (which will take a long time), it first sends a short control message to other datacenters. The receiver of this ASP selective barrier message blocks its local workers from reading the specified parameters until it receives the significant updates from the sender of the barrier.
Mirror clock. This provides a final safety net implementing SSP across datacenters. When each parameter server receives all the updates from its local worker machines at the end of a clock (e.g., an iteration), it reports its clock to the servers that are in charge of the same parameters in the other data centers. When a server detects its clock is ahead of the slowest server, it blocks until the slowest mirror server catches up.


The experiments, running across 11 Amazon EC2 global regions and on a cluster that emulates EC2 WAN bandwidth, compare Gaia against the Baseline that uses BSP (Bulk Synchronous Parallelism) across all datacenters and inside a LAN.
What are some examples of advanced significance functions? ML users can define advanced significance functions to be used with Gaia, but this is not explored/explained much in the paper. This may be a hard thing to do even for advanced users.
Even though it is easier to improve bandwidth than latency, the paper focuses on the challenge imposed by the limited WAN bandwidth rather than the WAN latency. While the end metric for evaluation is completion time of training, the paper does not investigate the effect of network latency. How would the evaluations look if the improvements are investigated in correlation to latency rather than throughput limitations? (I guess we can have a rough idea on this, if we knew how much the barrier control message was used.)
Motivation
This paper proposes a framework to distribute an ML system across multiple datacenters, and train models at the same datacenter where the data is generated. This is useful because it avoids the need to move big data over wide-area networks (WANs), which can be slow (WAN bandwidth is about 15x less than LAN bandwidth), costly (AWS does not charge for inside datacenter communication but charges for WAN communication), and also prone to privacy or ownership concerns.Google's Federated Learning also considered similar motivations, and set out to reduce WAN communication. It worked as follows: 1) smartphones are sent the model by the master/datacenter parameter-server, 2) smartphones compute an updated model based on their local data over some number of iterations, 3) the updated models are sent from the smartphones to the datacenter parameter-server, 4) the datacenter parameter-server aggregates these models (by averaging) to construct the new global model, and 5) Repeat.
The Gaia paper does not cite Federated Learning paper, because they are likely submitted around the same time. There are many parallels between Gaia's approach and that of Federated Learning. Both are based on the parameter-server model, and both prescribe updating the model parameters in a relaxed/stale/approximate synchronous parallel fashion: several iterations are run in-situ before updating the "master" parameter-server. The difference is for Federated Learning there is a "master" parameter-server in the datacenter, whereas Gaia takes a peer-to-peer approach where each datacenter has a parameter-server, and updating the "master" datacenter means synchronizing the parameter-servers across the datacenters.
Approximate Synchronous Parallelism (ASP) idea
Gaia's Approximate Synchronous Parallelism (ASP) idea tries to eliminate insignificant communication between data centers while still guaranteeing the correctness of ML algorithms. ASP is motivated by the observation that the vast majority of updates to the global ML model parameters from each worker are insignificant, e.g., more than 95% of the updates may produce less than a 1% change to the parameter value. With ASP, these insignificant updates to the same parameter within a data center are aggregated (and thus not communicated to other data centers) until the aggregated updates are significant enough.ASP builds heavily on the Stale Synchronous Parallelism (SSP) idea for parameter-server ML systems. While SSP bounds how stale (i.e., old) a parameter can be, ASP bounds how inaccurate a parameter can be, in comparison to the most up-to-date value.
ASP allows the ML programmer to specify the function and the threshold to determine the significance of updates for each ML algorithm. The significance threshold has 2 parts: a hard and a soft threshold. The purpose of the hard threshold is to guarantee ML algorithm convergence, while that of soft threshold is to use underutilized WAN bandwidth to speed up convergence. In other words, the soft threshold provides an opportunistic synchronization threshold.
Architecture
The Gaia architecture is simple: It prescribes adding a layer of indirection to parameter-server model to account for multiple datacenter deployments.
The significance filter. ASP takes 2 inputs from user: (1) a significance function and (2) an initial significance threshold. A parameter server aggregates updates from the local worker machines and shares the aggregated updates with other datacenters when the aggregate becomes significant. To facilitate convergence to the optimal point, ASP automatically reduces the significance threshold over time: if the original threshold is v, then the threshold at iteration t of the ML algorithm is $\frac{v}{\sqrt{t}}$.

ASP selective barrier. When a parameter-server receives the significant updates at a rate that is higher than the WAN bandwidth can support, instead of sending updates (which will take a long time), it first sends a short control message to other datacenters. The receiver of this ASP selective barrier message blocks its local workers from reading the specified parameters until it receives the significant updates from the sender of the barrier.
Mirror clock. This provides a final safety net implementing SSP across datacenters. When each parameter server receives all the updates from its local worker machines at the end of a clock (e.g., an iteration), it reports its clock to the servers that are in charge of the same parameters in the other data centers. When a server detects its clock is ahead of the slowest server, it blocks until the slowest mirror server catches up.
Evaluation
The paper evaluates Gaia with 3 popular ML applications. Matrix Factorization (MF) is a technique commonly used in recommender systems. Topic Modeling (TM) is an unsupervised method for discovering hidden semantic structures (topics) in an unstructured collection of documents, each consisting of a bag (multi-set) of words. Image Classification (IC) is a task to classify images into categories, and uses deep learning and convolutional neural networks (CNNs). All applications use SGD-based optimization.
The experiments, running across 11 Amazon EC2 global regions and on a cluster that emulates EC2 WAN bandwidth, compare Gaia against the Baseline that uses BSP (Bulk Synchronous Parallelism) across all datacenters and inside a LAN.
Questions
Is this general enough? The introduction says this should apply for SGD based ML algorithms. But are there hidden/implicit assumptions?What are some examples of advanced significance functions? ML users can define advanced significance functions to be used with Gaia, but this is not explored/explained much in the paper. This may be a hard thing to do even for advanced users.
Even though it is easier to improve bandwidth than latency, the paper focuses on the challenge imposed by the limited WAN bandwidth rather than the WAN latency. While the end metric for evaluation is completion time of training, the paper does not investigate the effect of network latency. How would the evaluations look if the improvements are investigated in correlation to latency rather than throughput limitations? (I guess we can have a rough idea on this, if we knew how much the barrier control message was used.)





Comments