Paper summary " Encoding, Fast and Slow: Low-Latency Video Processing Using Thousands of Tiny Threads"
This paper was written earlier than the "PyWren: Occupy the Cloud" paper, and appeared in NSDI'17. In fact this paper has influenced PyWren. The related work says "After the submission of this paper, we sent a preprint to a colleague who then developed PyWren, a framework that executes thousands of Python threads on AWS Lambda. ExCamera’s mu framework differs from PyWren in its focus on heavyweight computation with C++-implemented Linux threads and inter-thread communication."
I had written about AWS Lambda earlier. AWS Lambda is a serverless computing framework (aka a cloud-function framework) designed to execute user-supplied Lambda functions in response to asynchronous events, e.g., message arrivals, file uploads, or API calls made via HTTP requests.
While AWS Lambda is designed for executing asynchronous lightweight tasks for web applications, this paper introduced the "mu" framework to run general-purpose massively parallel heavyweight computations on it. This is done via tricking Lambda workers into executing arbitrary Linux executables (like LinPack written in C++). The mu framework is showcased by deploying an ExCamera application for compute-heavy video encoding. The ExCamera application starts 5000-way parallel jobs with IPC on AWS Lambda.
The paper provides the mu framework as opensource software.
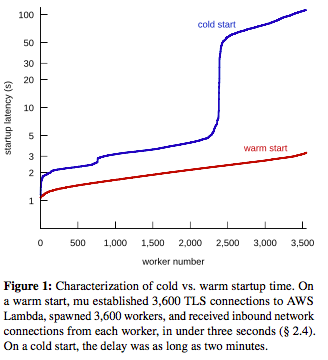 So if Lambda uses container technology, what is its difference from just using containers? The difference is that once invoked the container stays warm at some server waiting another invocation and this does not get charged to you since you are not actively using it. Lambda bills in 100ms increments, and only when you call the Lambda instance with a function invocation. In contrast, EC2 deploys in minutes and bills in hours, and the Google Compute Engine bills in 10 minute increments.
So if Lambda uses container technology, what is its difference from just using containers? The difference is that once invoked the container stays warm at some server waiting another invocation and this does not get charged to you since you are not actively using it. Lambda bills in 100ms increments, and only when you call the Lambda instance with a function invocation. In contrast, EC2 deploys in minutes and bills in hours, and the Google Compute Engine bills in 10 minute increments.
I think another significant difference is that Lambda forces you to use the container via function calls and in stateless mode. This is a limitation, but maybe this forced constraint accounts for most of the success/interest in this platform. Stateless and disaggregated way of doing things may be more amenable for scalability.
The mu platform has two important components external to the Lambda platform: the coordinator and the rendezvous center. And of course it has Lambda workers, thousands of them available on command.
In formats like 4K or virtual reality, an hour of video may take many hours to process as video compression relies on temporal correlations among nearby frames. However, ExCamera cuts this by an order of magnitude by deploying 1000s of Lambda workers in parallel and coordinating them via the mu platform.

As another application of the mu platform, the authors did a live demo for their NSDI17 conference talk. They had recorded 6 hours of video at the conference, and using OpenFace and mu platform on AWS Lambda they selected the frames where George Porter, a coauthor, appeared in the feed. This was done in minutes time and was indeed pretty bold thing to do at a presentation.
+ This is evaluated only on two videos.
+ If everybody used Lambda this way, would this still work?
+ The pipeline specification that the user should provide is complex.
+ A worker failure kills the entire job.
The paper mentions an experiment that ran 640 jobs, using 520,000 workers in total, each run for about a minute on average. In that experiment three jobs failed. This is a low failing rate, but this doesn't scale well with increasing job sizes.
I had written about AWS Lambda earlier. AWS Lambda is a serverless computing framework (aka a cloud-function framework) designed to execute user-supplied Lambda functions in response to asynchronous events, e.g., message arrivals, file uploads, or API calls made via HTTP requests.
While AWS Lambda is designed for executing asynchronous lightweight tasks for web applications, this paper introduced the "mu" framework to run general-purpose massively parallel heavyweight computations on it. This is done via tricking Lambda workers into executing arbitrary Linux executables (like LinPack written in C++). The mu framework is showcased by deploying an ExCamera application for compute-heavy video encoding. The ExCamera application starts 5000-way parallel jobs with IPC on AWS Lambda.
The paper provides the mu framework as opensource software.
Going from Lambda to Mu
The Lambda idea is that the user offloads her code to the cloud provider, and the provider provisions the servers and runs her code. It is easy to start 1000s of threads in parallel in sub-second startup latency (assuming warm Lambda instances). Upon receiving an event, AWS Lambda spawns a worker, which executes in a Linux container with up to two 2.8 GHz virtual CPUs, 1,536 MiB RAM, and about 500 MB of disk space.
I think another significant difference is that Lambda forces you to use the container via function calls and in stateless mode. This is a limitation, but maybe this forced constraint accounts for most of the success/interest in this platform. Stateless and disaggregated way of doing things may be more amenable for scalability.
The mu platform has two important components external to the Lambda platform: the coordinator and the rendezvous center. And of course it has Lambda workers, thousands of them available on command.
The mu coordinator
The mu platform has an explicit coordinator. (Recall that the PyWren platform design had a thin shim driver at the laptop.) The coordinator is a long-lived server (e.g., an EC2 VM) that launches jobs and controls their execution. The coordinator is truly the puppeteer. It manipulates the actions of each Lambda workers individually, and the workers comply as drones. The coordinator contains all of the logic associated with a given computation in the form of per-worker finite-state-machine (FSM) descriptions. For each worker, the coordinator maintains an open TLS connection, the worker’s current state, and its state-transition logic. When the coordinator receives a message from a worker, it applies the state-transition logic to that message, producing a new state and sending the next RPC request to the worker using the AWS Lambda API calls. (These HTTP requests are a bottleneck when launching thousands of workers, so the coordinator uses many parallel TCP connections to the HTTP server--one per worker-- and submits all events in parallel.) For computations in which workers depend on outputs from other workers, mu’s coordinator uses dependency-aware scheduling: the coordinator first assigns tasks whose outputs are consumed, then assigns tasks that consume those outputs.The Lambda workers
The workers are short-lived Lambda function invocations. All workers in mu use the same generic Lambda function. The user only installs one Lambda function and workers spawn quickly because the function remains warm. The user can include additional executables in the mu worker Lambda function package. The worker can then execute these in response to RPCs from the coordinator. The coordinator can instruct the worker to retrieve from or upload to AWS S3, establish connections to other workers via a rendezvous server, send data to workers over such connections, or run an executable.The mu rendezvous server
The mu platform employs a rendezvous server that helps each worker communicate with other workers. Like the coordinator, the rendezvous server is long lived. It stores messages from workers and relays them to their destination. This means that the rendezvous server’s connection to the workers can be a bottleneck, and thus fast network connectivity between workers and the rendezvous is required.Using the mu platform
To design a computation, a user specifies each worker’s sequence of RPC requests and responses in the form of a FSM, which the coordinator executes. The simplest of mu’s state-machine components represents a single exchange of messages: the coordinator waits for a message from the worker, sends an RPC request, and transitions unconditionally to a new state. To encode control-flow constructs like if-then-else and looping, the mu Python library includes state combinator components. An if-then-else combinator might check whether a previous RPC succeeded, only uploading a result to S3 upon success.ExCamera video encoding application
The paper implements a video encoder intended for fine-grained parallelism, called ExCamera. ExCamera encodes tiny chunks of the video in independent threads (doing most of the “slow” work in parallel), then stitches those chunks together in a “fast” serial pass, using an encoder written in explicit state-passing style with named intermediate states.In formats like 4K or virtual reality, an hour of video may take many hours to process as video compression relies on temporal correlations among nearby frames. However, ExCamera cuts this by an order of magnitude by deploying 1000s of Lambda workers in parallel and coordinating them via the mu platform.
As another application of the mu platform, the authors did a live demo for their NSDI17 conference talk. They had recorded 6 hours of video at the conference, and using OpenFace and mu platform on AWS Lambda they selected the frames where George Porter, a coauthor, appeared in the feed. This was done in minutes time and was indeed pretty bold thing to do at a presentation.
Limitations
The paper has a limitations section. (I always wanted to include such a section in my papers. Maybe by including the limitations section you can preemptively disarm straightforward criticisms.) The limitations lists:+ This is evaluated only on two videos.
+ If everybody used Lambda this way, would this still work?
+ The pipeline specification that the user should provide is complex.
+ A worker failure kills the entire job.
The paper mentions an experiment that ran 640 jobs, using 520,000 workers in total, each run for about a minute on average. In that experiment three jobs failed. This is a low failing rate, but this doesn't scale well with increasing job sizes.





Comments