Paper summary: Zorua: A holistic approach to resource virtualization in GPU
This paper recently appeared in MICRO'16 and addresses the problem of ease of managing GPU as a computational resource.
GPU computing today struggles with the following problems:
To address the above problems, Zorua (named after the shapeshifting illusionist Pokemon) virtualizes the GPU resources (threads, registers, and scratchpad). Zorua gives the illusion of more GPU resources than physically available, and dynamically manages these resources behind the scenes to co-host multiple applications on the GPU, alleviating the dynamic underutilization problem alluded above.
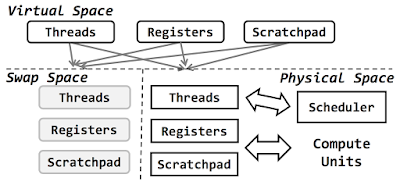
To create this illusion, Zorua employs a hardware-software codesign that consists of 3 components: (1) the compiler annotates the program to specify the resource needs of each phase of the application; (2) a runtime system, referred to as the coordinator, uses the compiler annotations to dynamically manage the virtualization of the different on-chip resources; and (3) the hardware employs mapping tables to locate a virtual resource in the physically available resources or in the swap space in main memory.
Of course, this illusion will fail when you try to cram more than feasible to the GPU. But the nice thing about Zorua is it fails gracefully: The coordinator component of Zorua schedules threads only when the expected gain in thread-level parallelism outweighs the cost of transferring oversubscribed resources from the swap space in memory.
One thing that I wondered was why Zorua needed the compiler annotation, and why the runtime alone was not sufficient. I think the compiler annotation helps buy us the graceful degradation property. GPU computing is not very nimble; it has a lot of staging overhead. The annotations give a heads up to the coordinator for planning the scheduling in an overhead-aware manner.
The paper does not mention any application of Zorua for machine learning applications. I think Zorua would be useful for making DNN serving/inference applications colocate on the same GPU and preventing the server-sprawl problem, as it alleviates the dynamic underutilization problem.
I wonder if Zorua can provide benefits for machine learning training. Since machine learning training is done in batch, it would utilize GPU pretty consistently, stalling briefly in between rounds/iterations. However, by running two iterations in off-step manner as in Stale-Synchronous Parallelism, it may be possible to get benefit from Zorua GPU virtualization.
A related work for using GPUs efficiently for Deep Learning is the Poseidon work. Poseidon optimizes the pipelining of GPU computing at a very fine granularity, at the sub DNN layer, to eliminate the stalling/idle-waiting of the GPU.
GPU computing today struggles with the following problems:
- Programming ease: The programmer needs to statically allocate GPU resources (registers, scratchpad, threads) to threads and this is hard and non-optimal as tuning is hard.
- Portability: An optimized specification on one GPU may be suboptimal (losing upto 70% performance) on another GPU.
- Performance: Since the programmer allocates resources statically and fixed manner, the performance suffer and dynamic underutilization occur when the program resource utilization vary through execution.
To address the above problems, Zorua (named after the shapeshifting illusionist Pokemon) virtualizes the GPU resources (threads, registers, and scratchpad). Zorua gives the illusion of more GPU resources than physically available, and dynamically manages these resources behind the scenes to co-host multiple applications on the GPU, alleviating the dynamic underutilization problem alluded above.

To create this illusion, Zorua employs a hardware-software codesign that consists of 3 components: (1) the compiler annotates the program to specify the resource needs of each phase of the application; (2) a runtime system, referred to as the coordinator, uses the compiler annotations to dynamically manage the virtualization of the different on-chip resources; and (3) the hardware employs mapping tables to locate a virtual resource in the physically available resources or in the swap space in main memory.
Of course, this illusion will fail when you try to cram more than feasible to the GPU. But the nice thing about Zorua is it fails gracefully: The coordinator component of Zorua schedules threads only when the expected gain in thread-level parallelism outweighs the cost of transferring oversubscribed resources from the swap space in memory.
One thing that I wondered was why Zorua needed the compiler annotation, and why the runtime alone was not sufficient. I think the compiler annotation helps buy us the graceful degradation property. GPU computing is not very nimble; it has a lot of staging overhead. The annotations give a heads up to the coordinator for planning the scheduling in an overhead-aware manner.
The paper does not mention any application of Zorua for machine learning applications. I think Zorua would be useful for making DNN serving/inference applications colocate on the same GPU and preventing the server-sprawl problem, as it alleviates the dynamic underutilization problem.
I wonder if Zorua can provide benefits for machine learning training. Since machine learning training is done in batch, it would utilize GPU pretty consistently, stalling briefly in between rounds/iterations. However, by running two iterations in off-step manner as in Stale-Synchronous Parallelism, it may be possible to get benefit from Zorua GPU virtualization.
A related work for using GPUs efficiently for Deep Learning is the Poseidon work. Poseidon optimizes the pipelining of GPU computing at a very fine granularity, at the sub DNN layer, to eliminate the stalling/idle-waiting of the GPU.





Comments