Paper Review. Petuum: A new platform for distributed machine learning on big data
First there was big data. Industry saw that big data was good. Industry made big data storage systems, NoSQL datastores, to store and access the big data. Industry saw they were good. Industry made big data processing systems, Map Reduce, Spark, etc., to analyze and extract information and insights (CRM, business logistics, etc.) from big data. Industry saw they were good and popular, so machine learning libraries are added to these big data processing systems to provide support for machine learning algorithms and techniques.
And here is where this paper makes a case for a redesign for machine learning systems. The big data processing systems produced by the industry are general analytic systems, and are not specifically designed for machine learning from the start. Those are data analytics frameworks first, with some machine learning libraries as add on to tackle machine learning tasks. This paper considers the problem of a clean slate system design for a big data machine learning system: What if we designed and built a big data framework specifically for machine learning systems, what would it look like?
This paper is from CMU and appeared in KDD 2015.
Thus, the paper argues, ML algorithms have an iterative-convergent structure and share these principles:
The paper proposes Petuum, a new distributed ML framework, to leverage these principles.
While the BSP (Bulk Synchronous Parallel) approach, used in Map Reduce, Giraph, etc., require the workers to synchronize state and exchange messages after each round, SSP cuts some slack. The SSP consistency model guarantees that if a worker reads from parameter server at iteration c, it is guaranteed to receive all updates from all workers computed at least at iteration c-s-1, where s is the staleness threshold. If there is a straggler more than s iterations behind, the reader will stop until the straggler catches up and sends its updates. How do you determine slack, s? That requires ML expertise and experimenting.

Another significant idea in the Petuum paper is the dichotomy between big data and big model. Yes, big data is big, on the order of terabytes or petabytes. And the paper observes, we now also have a big model problem: ML programs for industrial-scale big data problems use big models that are 100s of billions of parameters (Figure 1 gives a nice summary). And this big model needs special attention as well.
Here I will use snippets from the paper to give the proper definition of these concepts.



Essentially, model-parallelism provides ability to invoke dynamic schedules that reduce model parameter dependencies across workers, leading to faster convergence. So Petuum uses model-parallelism to leverage nonuniform convergence and dynamic structure dependency to improve the efficiency/performance of ML tasks.


The scheduler is responsible for enabling model parallelism. Scheduler sends subset of parameters to workers via parameter exchange channel. The parameter server stores and updates model paramerters., which can be accessed via a distributed shared memory API by both workers and scheduler. Each worker is responsible for performing operations defined by a user on a partitioned data set and a parameter subset specified by scheduler.
Here is the Petuum API:
schedule: specify the subset of model parameters to be updated in parallel.
push: specify how individual workers compute partial results on those parameters.
pull [optional]: specify how those partial results are aggregtaed to perform the full parameter update.
To illustrate the use of Petuum API, the paper presents the code for a data-parallel Distance Metric Learning (DML) algorithm and for a model parallel Lasso algorithm.


It looks like writing an efficient/optimized schedule would need significant expertise. This will often require running the algorithm on test dataset to see relations between model parameters, convergence speeds, etc.

There would be advantages/disadvantages for each approach, and it will be interesting to watch how this plays out in the coming years.
And here is where this paper makes a case for a redesign for machine learning systems. The big data processing systems produced by the industry are general analytic systems, and are not specifically designed for machine learning from the start. Those are data analytics frameworks first, with some machine learning libraries as add on to tackle machine learning tasks. This paper considers the problem of a clean slate system design for a big data machine learning system: What if we designed and built a big data framework specifically for machine learning systems, what would it look like?
This paper is from CMU and appeared in KDD 2015.
Machine Learning (ML) objectives and features
Naturally the paper starts by first identifying the objective and features of ML systems. "ML defines an explicit objective function over data where the goal is to attain optimality of this function in the space defined by the model parameters and other intermediate variables."Thus, the paper argues, ML algorithms have an iterative-convergent structure and share these principles:
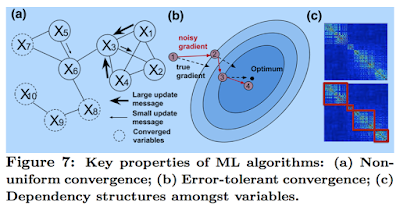
- nonuniform convergence: model parameters converge at different speeds
- error tolerance: iterative-convergent algorithms are resilient against errors and converge/heal towards the solution
- dynamic structure dependency: iterative-convergent algorithms often have changing correlation strengths between model parameters during the course of execution

The paper proposes Petuum, a new distributed ML framework, to leverage these principles.
Stale Synchronous Parallel (SSP) consistency
Petuum leverages error-tolerance by introducing SSP (Stale Synchronous Parallel) consistency. SSP reduces network synchronization costs among workers, while maintaining bounded staleness convergence guarantees.While the BSP (Bulk Synchronous Parallel) approach, used in Map Reduce, Giraph, etc., require the workers to synchronize state and exchange messages after each round, SSP cuts some slack. The SSP consistency model guarantees that if a worker reads from parameter server at iteration c, it is guaranteed to receive all updates from all workers computed at least at iteration c-s-1, where s is the staleness threshold. If there is a straggler more than s iterations behind, the reader will stop until the straggler catches up and sends its updates. How do you determine slack, s? That requires ML expertise and experimenting.
Big data, meet Big model!

Another significant idea in the Petuum paper is the dichotomy between big data and big model. Yes, big data is big, on the order of terabytes or petabytes. And the paper observes, we now also have a big model problem: ML programs for industrial-scale big data problems use big models that are 100s of billions of parameters (Figure 1 gives a nice summary). And this big model needs special attention as well.
Here I will use snippets from the paper to give the proper definition of these concepts.



Essentially, model-parallelism provides ability to invoke dynamic schedules that reduce model parameter dependencies across workers, leading to faster convergence. So Petuum uses model-parallelism to leverage nonuniform convergence and dynamic structure dependency to improve the efficiency/performance of ML tasks.

Petuum design
Petuum consists of three main components: Scheduler, parameter server, and workers.
The scheduler is responsible for enabling model parallelism. Scheduler sends subset of parameters to workers via parameter exchange channel. The parameter server stores and updates model paramerters., which can be accessed via a distributed shared memory API by both workers and scheduler. Each worker is responsible for performing operations defined by a user on a partitioned data set and a parameter subset specified by scheduler.
Here is the Petuum API:
schedule: specify the subset of model parameters to be updated in parallel.
push: specify how individual workers compute partial results on those parameters.
pull [optional]: specify how those partial results are aggregtaed to perform the full parameter update.
To illustrate the use of Petuum API, the paper presents the code for a data-parallel Distance Metric Learning (DML) algorithm and for a model parallel Lasso algorithm.


It looks like writing an efficient/optimized schedule would need significant expertise. This will often require running the algorithm on test dataset to see relations between model parameters, convergence speeds, etc.
Evaluation
The paper provides evaluation results on the performance of Petuum.
Petuum versus TensorFlow
How does Petuum compare with Google's TensorFlow? TensorFlow framework can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models. And yet, TensorFlow has a completely different design approach than Petuum. Tensorflow uses dataflow graphs. Implementing a ML algorithm/recipe on TensorFlow has a more distributed nature. An algorithm/recipe consists of many operations, and TensorFlow maps one or multiple operations in this algorithm to a node/worker. In Petuum the entire algorithm/recipe is mapped on a node/worker and efficiency is achieved via data-parallel and model-parallel partitioning.There would be advantages/disadvantages for each approach, and it will be interesting to watch how this plays out in the coming years.





Comments