Large-scale cluster management at Google with Borg
This paper is by Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes and it appeared recently in EuroSys 2015.
Google's Borg is a cluster manager that admits, schedules, starts, restarts, and monitors all applications that Google runs. Borg runs 100K of jobs across a number of clusters each with 10K of machines.
Borg cells (1000s of machines that belong to a single cluster and are managed as a unit) run a heterogenous workload with two main parts. The first is long-running services that should never go down, and handle quick requests: e.g., Gmail, Google Docs, web search, BigTable. The second is user submitted batch jobs. Each job consists of multiple tasks that all run the same program (binary).
Each task maps to a set of Linux processes running in a container on a machine. The vast majority of the Borg workload does not run inside virtual machines (VMs) in order to avoid the cost of virtualization. Containers are so hot right now.
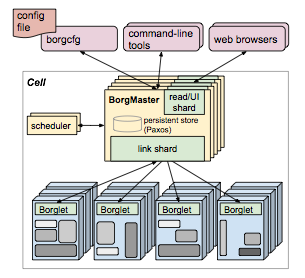
The Borgmaster process handles client RPCs to create, edit, view job, and also communicates with the Borglets to monitor/maintain their state. (The Borglet is a machine-local Borg agent that starts, stops, restarts tasks at a machine. The Borgmaster polls each Borglet every few seconds to retrieve the machine's current state and send it any outstanding requests.) The Borgmaster process is logically a single process but is actually Paxos replicated over 5 servers.
When a job is submitted, the Borgmaster records it in Paxos and adds the job's tasks to the pending queue. This is scanned asynchronously by the scheduler, which assigns tasks to machines if there are sufficient available resources that meet the job's constraints. The scheduling algorithm has two parts: feasibility checking, to find machines on which the task could run, and scoring, which picks one of the feasible machines. If the machine selected by the scoring phase doesn't have enough available resources to fit the new task, Borg preempts (kills) lower-priority tasks, from lowest to highest priority, until it does.
One early technique they used for scalability of the Borgmaster is to decouple the Borgmaster into a master process and an asynchronous scheduler. A scheduler replica operates on a cached copy of the cell state from the Borgmaster in order to perform a scheduling pass to assign tasks. The master will accept and apply these assignments unless they are inappropriate (e.g., based on out of date state), just like in optimistic concurrency control (OCC). To improve response times, they added separate threads to talk to the Borglets and respond to read-only RPCs.
A single Borgmaster can manage many thousands of machines in a cell, and several cells have arrival rates above 10000 tasks per minute. A busy Borgmaster uses 10–14 CPU cores and up to 50 GiB RAM.
In order to achieve the scalability of the scheduler, Borg employs score caching, grouping & treating tasks in equivalence classes, and performing relaxed randomization (basically sampling on machines). These reduced the scheduling time of a cell's entire workload from scratch from 3 days to a few 100s of seconds. Normally, an online scheduling pass over the pending queue completes in less than half a second.
AWS has ECS (EC2 Container Service) for managing jobs running on clusters. ECS has a state management system that runs Paxos to ensure a consistent and highly available view of the cluster state. (similar to the Borgmaster process). Instead of one scheduler, ECS employs distributed schedulers each interacting with the state management system. Each scheduler is responsible for a separate set of workers in order to avoid too many conflicts in scheduling decisions.
Microsoft has the Autopilot system for automating software provisioning, deployment, and system monitoring. Microsoft also uses the Apollo system for scheduling which tops-off workers opportunistically with short-lived batch jobs to achieve high throughput, with the cost of causing (occasionally) multi-day queueing delays for lower-priority work.
Kubernetes is under active development by many of the same engineers who built Borg. Kubernetes builds/improves on Borg. In Borg, a major headache was caused due to using one IP address per machine. That meant Borg had to schedule ports as a resource coordinate with tasks to resolve port conflicts in the same machine. Thanks to the advent of Linux namespaces, VMs, IPv6, and software-defined networking, Kubernetes can take a more user-friendly approach that eliminates these complications: every pod and service gets its own IP address. Kubernetes is opensource.
Google's Borg is a cluster manager that admits, schedules, starts, restarts, and monitors all applications that Google runs. Borg runs 100K of jobs across a number of clusters each with 10K of machines.
Borg cells (1000s of machines that belong to a single cluster and are managed as a unit) run a heterogenous workload with two main parts. The first is long-running services that should never go down, and handle quick requests: e.g., Gmail, Google Docs, web search, BigTable. The second is user submitted batch jobs. Each job consists of multiple tasks that all run the same program (binary).
Each task maps to a set of Linux processes running in a container on a machine. The vast majority of the Borg workload does not run inside virtual machines (VMs) in order to avoid the cost of virtualization. Containers are so hot right now.
Borgmaster
Each cell's Borgmaster consists of two processes: the main Borgmaster process and a separate scheduler.The Borgmaster process handles client RPCs to create, edit, view job, and also communicates with the Borglets to monitor/maintain their state. (The Borglet is a machine-local Borg agent that starts, stops, restarts tasks at a machine. The Borgmaster polls each Borglet every few seconds to retrieve the machine's current state and send it any outstanding requests.) The Borgmaster process is logically a single process but is actually Paxos replicated over 5 servers.
When a job is submitted, the Borgmaster records it in Paxos and adds the job's tasks to the pending queue. This is scanned asynchronously by the scheduler, which assigns tasks to machines if there are sufficient available resources that meet the job's constraints. The scheduling algorithm has two parts: feasibility checking, to find machines on which the task could run, and scoring, which picks one of the feasible machines. If the machine selected by the scoring phase doesn't have enough available resources to fit the new task, Borg preempts (kills) lower-priority tasks, from lowest to highest priority, until it does.
Scalability
"Centralized is not necessarily less scalable than decentralized" is a pet pieve of mine. So, I went all ears when I read this section. The paper said: "We are not sure where the ultimate scalability limit to Borg's centralized architecture will come from; so far, every time we have approached a limit, we've managed to eliminate it."One early technique they used for scalability of the Borgmaster is to decouple the Borgmaster into a master process and an asynchronous scheduler. A scheduler replica operates on a cached copy of the cell state from the Borgmaster in order to perform a scheduling pass to assign tasks. The master will accept and apply these assignments unless they are inappropriate (e.g., based on out of date state), just like in optimistic concurrency control (OCC). To improve response times, they added separate threads to talk to the Borglets and respond to read-only RPCs.
A single Borgmaster can manage many thousands of machines in a cell, and several cells have arrival rates above 10000 tasks per minute. A busy Borgmaster uses 10–14 CPU cores and up to 50 GiB RAM.
In order to achieve the scalability of the scheduler, Borg employs score caching, grouping & treating tasks in equivalence classes, and performing relaxed randomization (basically sampling on machines). These reduced the scheduling time of a cell's entire workload from scratch from 3 days to a few 100s of seconds. Normally, an online scheduling pass over the pending queue completes in less than half a second.
Related work
There is the Apache Mesos project, which originated from a UC Berkeley class project. Mesos formed the basis for Twitter's Aurora, a Borg-like scheduler for long running services, and Apple's Jarvis, which is used for running Siri services. Facebook has Tupperware, a Borg-like system for scheduling containers on a cluster.AWS has ECS (EC2 Container Service) for managing jobs running on clusters. ECS has a state management system that runs Paxos to ensure a consistent and highly available view of the cluster state. (similar to the Borgmaster process). Instead of one scheduler, ECS employs distributed schedulers each interacting with the state management system. Each scheduler is responsible for a separate set of workers in order to avoid too many conflicts in scheduling decisions.
Microsoft has the Autopilot system for automating software provisioning, deployment, and system monitoring. Microsoft also uses the Apollo system for scheduling which tops-off workers opportunistically with short-lived batch jobs to achieve high throughput, with the cost of causing (occasionally) multi-day queueing delays for lower-priority work.
Kubernetes is under active development by many of the same engineers who built Borg. Kubernetes builds/improves on Borg. In Borg, a major headache was caused due to using one IP address per machine. That meant Borg had to schedule ports as a resource coordinate with tasks to resolve port conflicts in the same machine. Thanks to the advent of Linux namespaces, VMs, IPv6, and software-defined networking, Kubernetes can take a more user-friendly approach that eliminates these complications: every pod and service gets its own IP address. Kubernetes is opensource.





Comments