Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
This paper is from Google. This is a refreshingly honest and humble paper. The paper is not pretending to be sophisticated and it doesn't have the "we have it all, we know it all" attitude. The paper presents the Dapper tool which is trying to solve a real problem, and it honestly represents how this simple straightforward solution fares and where it can be improved. This is the attitude of genuine researchers and seekers of truth.
It is sad to see that this paper did not get published in any conferences and is still listed as a Google Technical Report since April 2010. What was the problem? Not enough novelty? Not enough graphs?
It seems like performance monitoring was not the intended/primary use case for Dapper from the start though. Section 1.1 says this: The value of Dapper as a platform for development of performance analysis tools, as much as a monitoring tool in itself, is one of a few unexpected outcomes we can identify in a retrospective assessment.
Application-level transparency was achieved by restricting Dapper's core tracing instrumentation to a small corpus of ubiquitous threading, control flow, and RPC library code. In Google environment, since all applications use the same threading model, control flow and RPC system, it was possible to restrict instrumentation to a small set of common libraries, and achieve a monitoring system that is effectively transparent to application developers.
Making the system scalable and reducing performance overhead was facilitated by the use of adaptive sampling. The team found that a sample of just one out of thousands of requests provides sufficient information for many common uses of the tracing data.

Dapper performs trace logging and collection out-of-band with the request tree itself. Thus it is unintrusive on performance, and not paired to the application strongly.

The trace collection is asynchronous, and the trace is finally laid out as a single Bigtable row, with each column corresponding to a span. Bigtable's support for sparse table layouts is useful here since individual traces can have an arbitrary number of spans. In BigTable, it seems that the columns correspond to the "span names" in Figure 3, i.e., the name of the method called. The median latency for trace data collection is less than 15 seconds. The 98th percentile latency is itself bimodal over time; approximately 75% of the time, 98th percentile collection latency is less than two minutes, but the other approximately 25% of the time it can grow to be many hours. The paper does not mention about the reason of this very long tail, but this may be due to the batching fashion that the Dapper collectors work.
The paper lists the following Dapper use cases in Google:
Dapper is not intended to catch bugs in codes and track root causes of problems. It is useful for identifying which parts of a system is experiencing slowdowns.

It is sad to see that this paper did not get published in any conferences and is still listed as a Google Technical Report since April 2010. What was the problem? Not enough novelty? Not enough graphs?
Use case: Performance monitoring tail at scale
Dapper is Google's production distributed systems tracing infrastructure. The primary application for Dapper is performance monitoring to identify the sources of latency tails at scale. A front-end service may distribute a web query to many hundreds of query servers. An engineer looking only at the overall latency may know there is a problem, but may not be able to guess which of the dozens/hundreds of services is at fault, nor why it is behaving poorly. (See Jeff Dean and Barraso paper for learning more about the latency tails at scale).It seems like performance monitoring was not the intended/primary use case for Dapper from the start though. Section 1.1 says this: The value of Dapper as a platform for development of performance analysis tools, as much as a monitoring tool in itself, is one of a few unexpected outcomes we can identify in a retrospective assessment.
Design goals and overview
Dapper has three design goals:- Low overhead: the tracing system should have negligible performance impact on running services.
- Application-level transparency: programmers should not need to be aware of (write code for /instrument for) the tracing system.
- Scalability: Tracing and trace collection needs to handle the size of Google's services and clusters.
Application-level transparency was achieved by restricting Dapper's core tracing instrumentation to a small corpus of ubiquitous threading, control flow, and RPC library code. In Google environment, since all applications use the same threading model, control flow and RPC system, it was possible to restrict instrumentation to a small set of common libraries, and achieve a monitoring system that is effectively transparent to application developers.
Making the system scalable and reducing performance overhead was facilitated by the use of adaptive sampling. The team found that a sample of just one out of thousands of requests provides sufficient information for many common uses of the tracing data.
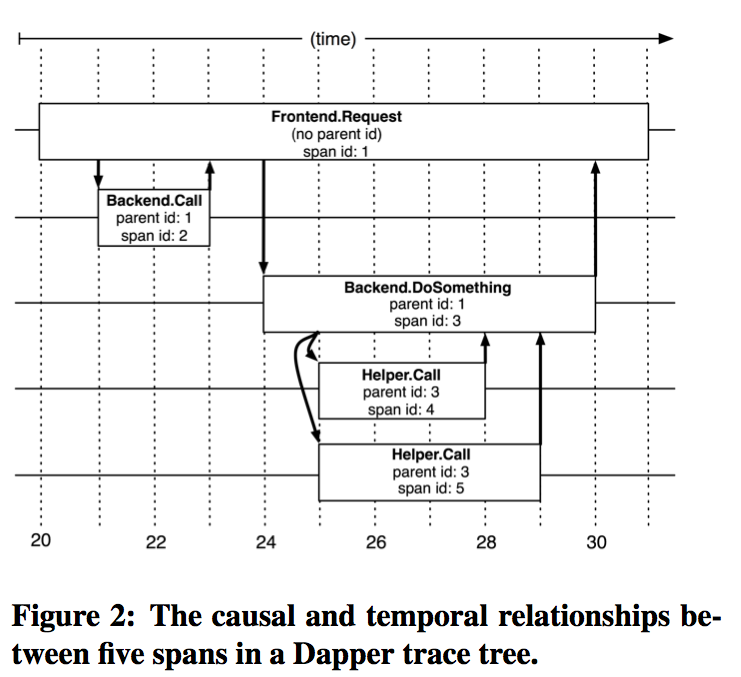
Trace trees and spans
Dapper explicitly tags every record with a global identifier that links the reports for generated messages/calls back to the originating request. In a Dapper trace tree, the tree nodes are basic units of work and are referred to as spans. The edges indicate a casual relationship between a span and its parent span. Span start and end times are timestamped with physical clocks, likely NTP time (or TrueTime?).Trace sampling and collection
The first production version of Dapper used a uniform sampling probability for all processes at Google, averaging one sampled trace for every 1024 candidates. This simple scheme was effective for the high-throughput online services since the vast majority of events of interest were still very likely to appear often enough to be captured.Dapper performs trace logging and collection out-of-band with the request tree itself. Thus it is unintrusive on performance, and not paired to the application strongly.
The trace collection is asynchronous, and the trace is finally laid out as a single Bigtable row, with each column corresponding to a span. Bigtable's support for sparse table layouts is useful here since individual traces can have an arbitrary number of spans. In BigTable, it seems that the columns correspond to the "span names" in Figure 3, i.e., the name of the method called. The median latency for trace data collection is less than 15 seconds. The 98th percentile latency is itself bimodal over time; approximately 75% of the time, 98th percentile collection latency is less than two minutes, but the other approximately 25% of the time it can grow to be many hours. The paper does not mention about the reason of this very long tail, but this may be due to the batching fashion that the Dapper collectors work.
Experiences and Applications of Dapper in Google
Dapper's daemon is part of Google's basic machine image and so Dapper is deployed across virtually all of Google's systems, and has allowed the vast majority of our largest workloads to be traced without need for any application-level modifications, and with no noticeable performance impact.The paper lists the following Dapper use cases in Google:
- Using Dapper during development (for the Google AdWords system)
- Addressing long tail latency
- Inferring service dependencies
- Network usage of different services
- Layered and shared storage services (for user billing and accounting for Google App Engine)
- Firefighting (trying to quickly-fix a distributed system in peril) with Dapper
Dapper is not intended to catch bugs in codes and track root causes of problems. It is useful for identifying which parts of a system is experiencing slowdowns.





Comments