PetaShare: A reliable, efficient and transparent distributed storage management system
This paper by my colleague Tevfik Kosar (to appear soon) presents the design and implementation of a reliable and efficient distributed data storage system, PetaShare, which manages 450 Terabytes of disk storage and spans 7 campuses across the state of Louisiana.
There are two main components in a distributed data management architecture: a data server which coordinates physical access (i.e. writing/reading data sets to/from disks) to the storage resources, and a metadata server which provides the global name space and metadata of the files. Metadata management is a challenging problem in widely distributed large-scale storage systems, and is the focus of this paper.
Petashare architecture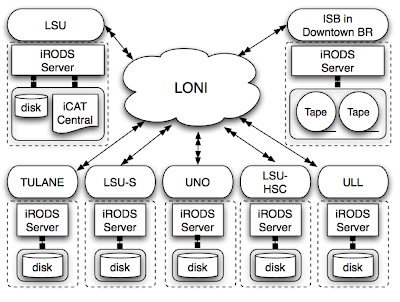 The back-end of PetaShare is based on iRODS. All system I/O calls made by an application are mapped to the relevant iRODS I/O calls. iRODS stores all the system information, as well as user-defined rules in centralized database, which is called iCAT. iCAT contains the information of the distributed storage resources, directories, files, accounts, metadata for files and system/user rules. iCAT is the metadata that we need to manage/distribute in PetaShare.
The back-end of PetaShare is based on iRODS. All system I/O calls made by an application are mapped to the relevant iRODS I/O calls. iRODS stores all the system information, as well as user-defined rules in centralized database, which is called iCAT. iCAT contains the information of the distributed storage resources, directories, files, accounts, metadata for files and system/user rules. iCAT is the metadata that we need to manage/distribute in PetaShare.
 The back-end of PetaShare is based on iRODS. All system I/O calls made by an application are mapped to the relevant iRODS I/O calls. iRODS stores all the system information, as well as user-defined rules in centralized database, which is called iCAT. iCAT contains the information of the distributed storage resources, directories, files, accounts, metadata for files and system/user rules. iCAT is the metadata that we need to manage/distribute in PetaShare.
The back-end of PetaShare is based on iRODS. All system I/O calls made by an application are mapped to the relevant iRODS I/O calls. iRODS stores all the system information, as well as user-defined rules in centralized database, which is called iCAT. iCAT contains the information of the distributed storage resources, directories, files, accounts, metadata for files and system/user rules. iCAT is the metadata that we need to manage/distribute in PetaShare.Multiple iRODS servers interact with the iCAT server to control the accesses to physical data in the resources. Of course, the centralized iCAT server is a single point of failure, and the entire system becomes unavailable when the iCAT server fails. As we discuss next, PetaShare employs asynchronous replication of iCAT to resolve this problem.
Asynchronous multi-master metadata replication
PetaShare first experimented with synchronous replication of the iCAT server. Not surprisingly, this led to high latency and performance degradation on data transfers, because each transfer could be committed only after iCAT servers complete replication. To eliminate this problem, PetaShare adopted an asynchronous replication system.
The biggest problem of asynchronous multi-master replication is that conflicts occur if two sites update their databases within the same replication cycle. For this reason, the proposed multi-master replication method should detect and resolve conflicts. Petashare uses a conceptual conflict resolver that handles such conflicts. Common conflict types are: (i) uniqueness conflicts: occur if two or more sites try to insert the records with the same primary key; (ii) update conflicts: occur if two or more sites try to update the same record within the same replication cycle; (iii) delete conflicts: occur if one site deletes a record from database while another site tries to update this record.
To prevent uniqueness conflicts, ID intervals are pre-assigned to different sites. (This could as well be achieved by prefacing IDs with the site ids.) Update conflicts are handled using the latest write rule if not resolved within a day, but there is a one-day grace period where negotiation (manual conflict handling) can be used. Delete conflicts are also handled similar to update conflicts.
Evaluation
The paper provides real-deployment experiment results on centralized, synchronous, and asynchronous replicated metadata servers. The no-replication column indicates using a centralized metadata server. Table 2 lets us to evaluate the performance of replication methods because the contribution of data transfer to the latency is minimized. For all data sets the asynchronous replication method outperforms the others, since both write and database operations are done locally. Similar to Table1, the central iCAT model gives better results than synchronous replication.
The no-replication column indicates using a centralized metadata server. Table 2 lets us to evaluate the performance of replication methods because the contribution of data transfer to the latency is minimized. For all data sets the asynchronous replication method outperforms the others, since both write and database operations are done locally. Similar to Table1, the central iCAT model gives better results than synchronous replication.





Comments