Amazon Aurora: Design Considerations + On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
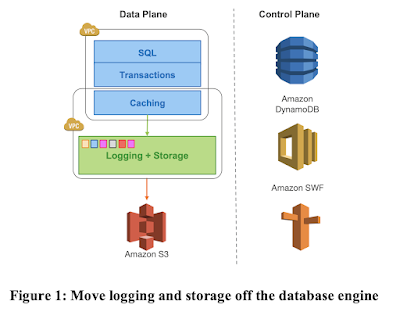
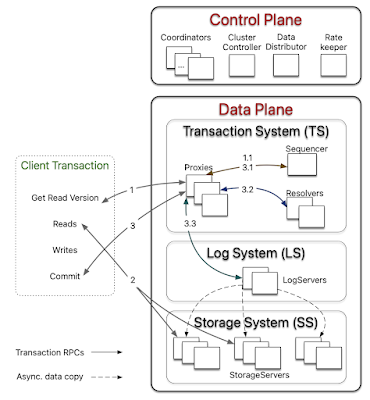
Amazon Aurora is a high-throughput cloud-native relational database. I will summarize its design as covered by the Sigmod 17 and Sigmod 18 papers from the Aurora team. Aurora uses MySQL or PostgreSQL for the database instance at top, and decouples the storage to a multi-tenant scale-out storage service. In this decoupled architecture, each database instance acts as a SQL endpoint and supports query processing, access methods, transactions, locking, buffer caching, and undo management. Some database functions, including redo logging, materialization of data blocks, garbage collection, and backup/restore, are offloaded to the storage nodes. A big innovation in Aurora is to do the replication among the storage nodes by pushing the redo log; this reduces networking traffic and enables fault-tolerant storage that heals without database involvement. In contrast to CockroachDB and FoundationDB , Aurora manages not to use consensus at all. It uses a primary secondary failover at the ...