Silent data corruptions at scale
This paper from Facebook (Arxiv Feb 2021) is referred in the Google fail-silent Corruption Execution Errors (CEEs) paper as the most related work. Both papers discuss the same phenomenon, and say that we need to update our belief about quality-tested CPUs not having logic errors, and that if they had an error it would be a fail-stop or at least fail-noisy hardware errors triggering machine checks.
This paper provides an account of how Facebook have observed CEEs over several years. After running a wide range of silent error test scenarios across 100K machines, they found that 100s of CPUs are identified as having these errors, showing that CEEs are a systemic issue across generations. This paper, as the Google paper, does not name specific vendor or chipset types. Also the ~1/1000 ratio reported here matches the ~1/1000 mercurial core ratio that the Google paper reports.
The paper claims that silent data corruptions can occur due to device characteristics and are repeatable at scale. They observed that these failures are reproducible and not transient. Then, how come did these CPUs pass the quality control tests by the chip producers? In soft-error based fault injection studies by chip producers, CPU CEEs are evaluated to be a one in a million occurrence, not 1 in 1000 observed at deployment at Facebook and Google. The paper says that CPU CEEs occur at a higher rate due to minimal error correction within functional blocks. I think different environment conditions (frequency, voltage, temperature) and aging/wearing also plays a role in increased error rates.
The paper also says that increased density, technology scaling, and wider datapaths increase the probability of silent errors. It claims CEEs is not limited to CPUs and is applicable to special function accelerators and other devices with wide datapaths.
Application level impact of silent corruptions
The paper gives an example of an actual CEE detected in a Spark deployment, and says that this would lead data loss.
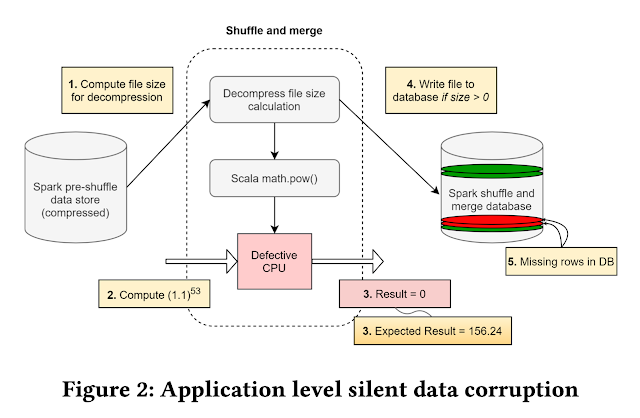
"In one such computation, when the file size was being computed, a file with a valid file size was provided as input to the decompression algorithm, within the decompression pipeline. The algorithm invoked the power function provided by the Scala library (Scala: A programming language used for Spark). Interestingly, the Scala function returned a 0 size value for a file which was known to have a non-zero decompressed file size. Since the result of the file size computation is now 0, the file was not written into the decompressed output database.
Imagine the same computation being performed millions of times per day. This meant for some random scenarios, when the file size was non-zero, the decompression activity was never performed. As a result, the database had missing files. The missing files subsequently propagate to the application. An application keeping a list of key value store mappings for compressed files immediately observes that files that were compressed are no longer recoverable. This chain of dependencies causes the application to fail. Eventually the querying infrastructure reports critical data loss after decompression. The problem’s complexity is magnified as this manifested occasionally when the user scheduled the same workload on a cluster of machines. This meant the patterns to reproduce and debug were non-deterministic."
They also explain how they debugged and root-caused this problem.

"Once the reproducer is obtained in assembly language, we optimize the assembly for efficiency. The assembly code accurately reproducing the defect is reduced to a 60-line assembly level reproducer. We started with a 430K line reproducer and narrowed it down to 60 lines. Figure 3 provides a high level debug flow followed for root-causing silent errors."
Musings
The closest I worked to the metal was between 2000-2005, when I worked hands on with 100s of wireless sensor network nodes. We routinely found bad sensor boards (with spurious detections or no detections at all) and bad radios. Generally bad radios came in pair: when the frequency of two radios differ significantly from each other, those two could not talk to each other, but neither of them had issue talking to some other radios.
With low quality control, the sensor nodes had higher rate of bad sensors and radios. I guess there is a big analog component involved in sensors and radios in contrast to chips as well. We did not really observe fail-safe CEEs, but who knows. We didn't have access to 100K nodes, and we didn't have good observation in to node computations: since the nodes are low-power and have limited resources it was hard to extract detailed log information from them.





Comments