Exploiting Commutativity For Practical Fast Replication (NSDI'19)
This paper appeared in NSDI'19, and is by Seo Jin Park and John Ousterhout. You can access the paper as well as the conference presentation video here.
Here is also a YouTube link to a presentation of the paper in our Zoom DistSys reading group. This was the 10th paper we discussed in our Zoom group. We have been meeting on Zoom every Wednesday since April 1st at 15:30 EST. Join our Slack channel to get paper information, discussion and meeting links https://join.slack.com/t/distsysreadinggroup/shared_invite/zt-eb853801-3qEpQ5xMyXpN2YGvUo~Iyg
Of course, if we were to do asynchronous replication, we could get 1 RTT. The client would contact the leader in the replication group, the leader will acknowledge back and start replicating to backups/followers asynchronously. The problem with this scheme is that it is not fault-tolerant. The leader may crash after acking the write, and the client would lose read-your-own-write guarantee, let alone linearizability.
The paper introduces the Consistent Unordered Replication Protocol (CURP) to address this problem. CURP augments the above asynchronous replication scheme with a temporary stash for fault-tolerance.
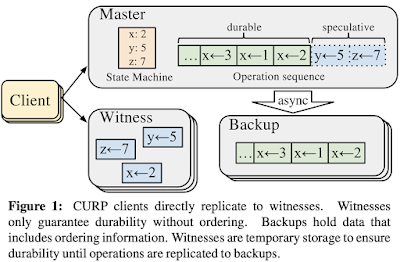
Since the master returns to clients before replication to backups, we get 1 RTT updates. The use of the witnesses ensures durability. Once all f witnesses have accepted the requests, clients are assured that the requests will survive master crashes, so clients complete the operations with the results returned from masters. If the master indeed crashes, information from witnesses is combined with that from the normal replicas to re-create a consistent server state.

This 1 RTT completion only works for commutative operations, whose order of execution does not matter. It won't work for non-commutative operations because the witnesses do not (and cannot in a consistent way) order operations they receive from clients as the order of arrival of operations may be different across the witnesses.
A witness accepts a new operation-record from a client only if the new operation is commutative with all operations that are currently saved in the witness. If the new request doesn't commute with one of the existing requests, the witness must reject the record RPC since the witness has no way to order the two non-commutative operations consistent with the execution order in masters. For example, if a witness already accepted "x :=1", it cannot accept "x:==5". Witnesses must be able to determine whether operations are commutative or not just from the operation parameters. For example, in key-value stores, witnesses can exploit the fact that operations on different keys are commutative.
Therefore, for a non-commutative operation, the client will not be able to receive ACKs from all f witnesses. In this case, to ensure the durability of the operation, the client must wait for replication to backups by sending a sync RPC to the master. Upon receiving a sync RPC, the master ensures the operation is replicated to backups before returning to the client. This waiting for sync increases the operation latency to 2 RTTs in most cases and up to 3 RTT in the worst case where the master hasn't started syncing until it receives a sync RPC from a client.
This is problematic. The quick communication from the master to the witnesses become critical for the performance of CURP. If operation records cannot be garbage-collected quickly, the performance suffers.
Even if we co-locate witnesses with backups, you still need an extra commit message from the leader for garbage collection. It may be possible to piggyback this garbage-collection message to another write, but still garbage collection being tied to performance is bad.
For the second part, the new master picks any available witness. After picking the witness to recover from, the new master first asks it to stop accepting more operations; this prevents clients from erroneously completing update operations after recording them in a stale witness whose requests will not be retried anymore. After making the selected witness immutable, the new master retrieves the requests recorded in the witness. Since all requests in a single witness are guaranteed to be commutative, the new master can execute them in any order.
This was for recovering from a master crash. There is added complexity for reconfiguration operations as well. The reconfiguration section discusses recovery of a crashed backup and recovery of a crashed witness as well.
CURP doesn’t change the way to handle backup failures, so a system can just recover a failed backup as it would without CURP.
If a witness crashes or becomes non-responsive, the system configuration manager (the owner of all cluster configurations) decommissions the crashed witness and assigns a new witness for the master; then it notifies the master of the new witness list. When the master receives the notification, it syncs to backups to ensure f-fault tolerance and responds back to the configuration manager that it is now safe to recover from the new witness. After this point, clients can use f witnesses again to record operations.
The fault-tolerance becomes messy, in my opinion. These paths are treated as exceptions, and are not tested/exercised as part of normal operations, and therefore are more prone to errors/bugs than the happy path.

It is possible to perform a read from a backup and a witness. If the witness says there is no request that is not commutative with the requested item, the client can read from the backup and this will be a linearizable read. I am not sure why a race condition is not possible in this case.
If the witness says, there is a non-commutative operation with the read, the read is sent to the master for getting served.



TAPIR is related work. I hope we will be reading the TAPIR paper in our Zoom reading group soon.
Here is also a YouTube link to a presentation of the paper in our Zoom DistSys reading group. This was the 10th paper we discussed in our Zoom group. We have been meeting on Zoom every Wednesday since April 1st at 15:30 EST. Join our Slack channel to get paper information, discussion and meeting links https://join.slack.com/t/distsysreadinggroup/shared_invite/zt-eb853801-3qEpQ5xMyXpN2YGvUo~Iyg
The problem
The paper considers performing consistent replication fast, in 1 round trip time (RTT) from client.Of course, if we were to do asynchronous replication, we could get 1 RTT. The client would contact the leader in the replication group, the leader will acknowledge back and start replicating to backups/followers asynchronously. The problem with this scheme is that it is not fault-tolerant. The leader may crash after acking the write, and the client would lose read-your-own-write guarantee, let alone linearizability.
The paper introduces the Consistent Unordered Replication Protocol (CURP) to address this problem. CURP augments the above asynchronous replication scheme with a temporary stash for fault-tolerance.
Happy path
CURP supplements the primary-backup replication system with a fault-tolerance stash: witness-based out-of-order lightweight replication. The client replicates each operation to the witnesses in parallel when sending the request to the primary server. The primary executes the operation and returns to the client without waiting for normal replication to its backups, which happens asynchronously. When the client hears from the f witnesses and the speculative reply from the primary, it considers the write to be completed.
Since the master returns to clients before replication to backups, we get 1 RTT updates. The use of the witnesses ensures durability. Once all f witnesses have accepted the requests, clients are assured that the requests will survive master crashes, so clients complete the operations with the results returned from masters. If the master indeed crashes, information from witnesses is combined with that from the normal replicas to re-create a consistent server state.

This 1 RTT completion only works for commutative operations, whose order of execution does not matter. It won't work for non-commutative operations because the witnesses do not (and cannot in a consistent way) order operations they receive from clients as the order of arrival of operations may be different across the witnesses.
Execution of non-commutative operations
Non-commutative operations require 2 or 3 RTTs, and work as follows.A witness accepts a new operation-record from a client only if the new operation is commutative with all operations that are currently saved in the witness. If the new request doesn't commute with one of the existing requests, the witness must reject the record RPC since the witness has no way to order the two non-commutative operations consistent with the execution order in masters. For example, if a witness already accepted "x :=1", it cannot accept "x:==5". Witnesses must be able to determine whether operations are commutative or not just from the operation parameters. For example, in key-value stores, witnesses can exploit the fact that operations on different keys are commutative.
Therefore, for a non-commutative operation, the client will not be able to receive ACKs from all f witnesses. In this case, to ensure the durability of the operation, the client must wait for replication to backups by sending a sync RPC to the master. Upon receiving a sync RPC, the master ensures the operation is replicated to backups before returning to the client. This waiting for sync increases the operation latency to 2 RTTs in most cases and up to 3 RTT in the worst case where the master hasn't started syncing until it receives a sync RPC from a client.
Garbage collection
To limit memory usage in witnesses and reduce possible rejections due to commutativity violations, witnesses must discard requests as soon as possible. Witnesses can drop the recorded client requests after masters make their outcomes durable in backups. In CURP, the master sends garbage collection RPCs for the synced updates to their witnesses.This is problematic. The quick communication from the master to the witnesses become critical for the performance of CURP. If operation records cannot be garbage-collected quickly, the performance suffers.
Even if we co-locate witnesses with backups, you still need an extra commit message from the leader for garbage collection. It may be possible to piggyback this garbage-collection message to another write, but still garbage collection being tied to performance is bad.
Crashes and recovery
CURP recovers from a master's crash in two phases: (1) the new master restores data from backups and then (2) it restores operations by replaying requests from witnesses.For the second part, the new master picks any available witness. After picking the witness to recover from, the new master first asks it to stop accepting more operations; this prevents clients from erroneously completing update operations after recording them in a stale witness whose requests will not be retried anymore. After making the selected witness immutable, the new master retrieves the requests recorded in the witness. Since all requests in a single witness are guaranteed to be commutative, the new master can execute them in any order.
This was for recovering from a master crash. There is added complexity for reconfiguration operations as well. The reconfiguration section discusses recovery of a crashed backup and recovery of a crashed witness as well.
CURP doesn’t change the way to handle backup failures, so a system can just recover a failed backup as it would without CURP.
If a witness crashes or becomes non-responsive, the system configuration manager (the owner of all cluster configurations) decommissions the crashed witness and assigns a new witness for the master; then it notifies the master of the new witness list. When the master receives the notification, it syncs to backups to ensure f-fault tolerance and responds back to the configuration manager that it is now safe to recover from the new witness. After this point, clients can use f witnesses again to record operations.
The fault-tolerance becomes messy, in my opinion. These paths are treated as exceptions, and are not tested/exercised as part of normal operations, and therefore are more prone to errors/bugs than the happy path.
Read operation

It is possible to perform a read from a backup and a witness. If the witness says there is no request that is not commutative with the requested item, the client can read from the backup and this will be a linearizable read. I am not sure why a race condition is not possible in this case.
If the witness says, there is a non-commutative operation with the read, the read is sent to the master for getting served.
Evaluation
CURP is implemented in RAMCloud and Redis to demonstrate its benefits.


Related work
This reminds me of the "Lineage Stash: Fault-tolerance off the critical path" paper in SOSP'19. It had a similar idea. Perform asynchronous replication but have enough stash to be able to recover and reconstruct the log if a failure occurs.TAPIR is related work. I hope we will be reading the TAPIR paper in our Zoom reading group soon.
What does Mad Danny say about the paper?
I asked Mad Danny about his views on the paper. This is what he had to say.- The closest thing to this is MultiPaxos. I would choose MultiPaxos over this, because it is well established implementation. MultiPaxos has very good throughput due to pipelining (see 2). Yes, it has 2RTT latency according to the measurement used in the CURP paper. But in reality it has 1RTT + 1 rtt latency. The all caps RTT is from the client to the leader and back. The lower case rtt is from the leader to the followers and back. In practice, the client is significantly farther away from the leader that these RTTs are different.
- MultiPaxos has very good throughput through the pipelining. The paper shows that CURP has 3.8x throughput than primary/backup because it cheats a little. It uses a small number of clients which are sending the operations in a synchronous way: the clients block until the previous operation is acknowledged. When there are enough clients (even when those clients are doing synchronous operation) the system is pushed to full utilization and MultiPaxos (or primary/backup) will give the same and maybe even better throughput than CURP, since CURP would have to deal with conflicts and sync. Check Figure 8 in the evaluation to see how quickly the throughput plummets in the presence of conflicts. Optimistic protocols, like EPaxos, all suffer from this problem.
- The tail-latency is bad in CURP. The client needs to hear from ALL witnesses and the master. So the operation speed is limited by the slowest node speed. MultiPaxos waits to hear from f out of 2f+1, the operation is as fast as the fastest half of the nodes, and is immune to the stragglers. This point was mentioned and explored in Physalia.
- The complexity for fault-tolerance reconfiguration that CURP introduces is not acceptable for a production system. There may be several cornercases and concurrency race conditions in the recovery and reconfiguration path. The cost of reconfiguration is high, and reconfiguration may be triggered unnecessarily in a false-positive manner in deployment.



Comments