Scaling Memcache at Facebook
This paper, which appeared in NSDI 2013, describes the evolution of Facebook’s memcached-based architecture. Memcached is an open-source implementation of a distributed in-memory hash table over a cluster of computers, and it is used for providing low latency access to a shared storage pool at low cost. Memcached was first developed by Brad Fitzpatrick in 2003.
Memcached at Facebook targets a workload dominated by reads (which are two orders of magnitude more frequent than writes). Facebook needs to support a very heavy read load, over 1 billion reads/second, and needs to insulate backend services from high read rates with very high fan-out. To this end, Facebook uses memcache as a "demand-filled look-aside cache". When a web server needs data, it first requests the value from memcache by providing a string key. If it is a cache hit, great, the read operation is served. If the item addressed by that key is not cached, the web server retrieves the data from the backend database and populates the cache with the key-value pair (for the benefit of the upcoming reads).
For write requests, the web server issues SQL statements to the database and then sends a delete request to memcache to invalidate the stale data, if any. Facebook chooses to delete cached data instead of updating it in cache because deletes are idempotent (which is a nice property to have in distributed systems). This is safe because memcache is not the authoritative source of the data and is therefore allowed to evict cached data.
Memcached servers do not communicate with each other. When appropriate, Facebook embeds the complexity of the system into a stateless client rather than in the memcached servers. Client logic is provided as two components: a library that can be embedded into applications or as a standalone proxy named mcrouter. Clients use UDP and TCP to communicate with memcached servers. These client-centric optimizations reduce incast-congestion at the servers (via application-specific UDP congestion control) and reduce load on the servers (via use of lease-tokens[like cookies] by the clients). The details are in the paper.
For handling failures of memcached nodes, Facebook uses the redundancy/slack idea. While Facebook relies on an automated remediation system for dealing with node failures, this can take up to a few minutes. This duration is long enough to cause cascading failures and thus Facebook uses a redundancy/slack mechanism to further insulate backend services from failures. Facebook dedicates a small set of machines, named Gutter, to take over the responsibilities of a few failed servers. Gutter accounts for approximately 1% of the memcached servers in a cluster. When a memcached client receives no response to its get request, the client assumes the server has failed and issues the request again to a special Gutter pool. If this second request misses, the client will insert the appropriate key-value pair into the Gutter machine after querying the database.
Note that this design differs from an approach in which a client rehashes keys among the remaining memcached servers. Such an approach risks cascading failures due to non-uniform key access frequency: a single key can account for 20% of a server’s requests. The server that becomes responsible for this hot key might also become overloaded. By shunting load to idle servers Facebook limits that risk. In practice, this system reduces the rate of client-visible failures by 99% and converts 10%–25% of failures into hits each day. If a memcached server fails entirely, hit rates in the gutter pool generally exceed 35% in under 4 minutes and often approach 50%. Thus when a few memcached servers are unavailable due to failure or minor network incidents, Gutter protects the backing store from a surge of traffic.
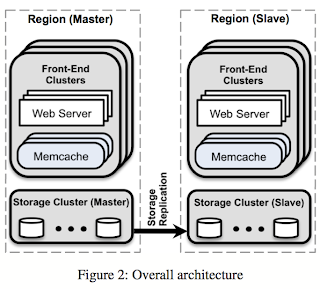

Facebook designates one region to hold the master databases and the other regions to contain read-only replicas, and relies on MySQL's replication mechanism to keep replica databases up-to-date with their masters. In this design, web servers can still experience low latency when accessing either the local memcached servers or the local database replicas.
system. 1) Separating cache and persistent storage systems via memcached allows for independently scaling them. 2) Managing stateful components is operationally more complex than stateless ones. As a result keeping logic in a stateless client helps iterate on features and minimize disruption. 3) Finally Facebook treats the probability of reading transient stale data as a parameter to be tuned, and is willing to expose slightly stale data in exchange for insulating a backend storage service from excessive load.
Related links
AWS seems to offer elasticache, which is protocol-compliant with Memcached.
There is also the RAMCloud project, which I had summarized earlier here.
Memcached at Facebook targets a workload dominated by reads (which are two orders of magnitude more frequent than writes). Facebook needs to support a very heavy read load, over 1 billion reads/second, and needs to insulate backend services from high read rates with very high fan-out. To this end, Facebook uses memcache as a "demand-filled look-aside cache". When a web server needs data, it first requests the value from memcache by providing a string key. If it is a cache hit, great, the read operation is served. If the item addressed by that key is not cached, the web server retrieves the data from the backend database and populates the cache with the key-value pair (for the benefit of the upcoming reads).
For write requests, the web server issues SQL statements to the database and then sends a delete request to memcache to invalidate the stale data, if any. Facebook chooses to delete cached data instead of updating it in cache because deletes are idempotent (which is a nice property to have in distributed systems). This is safe because memcache is not the authoritative source of the data and is therefore allowed to evict cached data.
In a Cluster: Reducing Latency and Load
Loading a popular page in Facebook results in fetching from memcache an average of 521 distinct items (a very high fan-out indeed), which have been distributed across the memcached servers through consistent hashing. All web servers communicate with every memcached server in a short period of time, and this all-to-all communication pattern can cause incast congestion or cause a single server to become the bottleneck for many web servers.Memcached servers do not communicate with each other. When appropriate, Facebook embeds the complexity of the system into a stateless client rather than in the memcached servers. Client logic is provided as two components: a library that can be embedded into applications or as a standalone proxy named mcrouter. Clients use UDP and TCP to communicate with memcached servers. These client-centric optimizations reduce incast-congestion at the servers (via application-specific UDP congestion control) and reduce load on the servers (via use of lease-tokens[like cookies] by the clients). The details are in the paper.
For handling failures of memcached nodes, Facebook uses the redundancy/slack idea. While Facebook relies on an automated remediation system for dealing with node failures, this can take up to a few minutes. This duration is long enough to cause cascading failures and thus Facebook uses a redundancy/slack mechanism to further insulate backend services from failures. Facebook dedicates a small set of machines, named Gutter, to take over the responsibilities of a few failed servers. Gutter accounts for approximately 1% of the memcached servers in a cluster. When a memcached client receives no response to its get request, the client assumes the server has failed and issues the request again to a special Gutter pool. If this second request misses, the client will insert the appropriate key-value pair into the Gutter machine after querying the database.
Note that this design differs from an approach in which a client rehashes keys among the remaining memcached servers. Such an approach risks cascading failures due to non-uniform key access frequency: a single key can account for 20% of a server’s requests. The server that becomes responsible for this hot key might also become overloaded. By shunting load to idle servers Facebook limits that risk. In practice, this system reduces the rate of client-visible failures by 99% and converts 10%–25% of failures into hits each day. If a memcached server fails entirely, hit rates in the gutter pool generally exceed 35% in under 4 minutes and often approach 50%. Thus when a few memcached servers are unavailable due to failure or minor network incidents, Gutter protects the backing store from a surge of traffic.
In a Region: Replication
Naively scaling-out this memcached system does not eliminate all problems. Highly requested items will become more popular as more web servers are added to cope with increased user traffic. Incast congestion also worsens as the number of memcached servers increases. They therefore split their web and memcached servers into multiple "regions". This region architecture also allows for smaller failure domains and a tractable network configuration. In other words, Facebook trades replication of data for more independent failure domains, tractable network configuration, and a reduction of incast congestion.

Across Regions: Consistency
When scaling across multiple regions, maintaining consistency between data in memcache and the persistent storage becomes the primary technical challenge. These challenges stem from a single problem: replica databases may lag behind the master database (this is a per-record master as in PNUTS). Facebook provides best-effort eventual consistency but place an emphasis on performance and availability.Facebook designates one region to hold the master databases and the other regions to contain read-only replicas, and relies on MySQL's replication mechanism to keep replica databases up-to-date with their masters. In this design, web servers can still experience low latency when accessing either the local memcached servers or the local database replicas.
Concluding remarks
Here are the lessons Facebook draws from their experience with the memcachedsystem. 1) Separating cache and persistent storage systems via memcached allows for independently scaling them. 2) Managing stateful components is operationally more complex than stateless ones. As a result keeping logic in a stateless client helps iterate on features and minimize disruption. 3) Finally Facebook treats the probability of reading transient stale data as a parameter to be tuned, and is willing to expose slightly stale data in exchange for insulating a backend storage service from excessive load.
Related links
AWS seems to offer elasticache, which is protocol-compliant with Memcached.
There is also the RAMCloud project, which I had summarized earlier here.



Comments