Warp: Lightweight Multi-Key Transactions for Key-Value Stores
This paper introduces a simple yet powerful idea to provide efficient multi-key transactions with ACID semantics on top of a sharded NoSQL data store. The Warp protocol prevents serializability cycles forming between concurrent transactions by forcing them to serialize via a chain communication pattern rather than using a parallel 2PC fan-out/fan-in communication. This avoids hotspots associated with fan-out/fan-in communication and prevents wasted parallel work from contacting multiple other servers when traversing them in serial would surface an invalidation/abortion early on in the serialization. I love the elegance of this idea.
As far as I can see, this paper did not get published in any conference. The authors published a followup paper to this in NSDI 16, called "The Design and Implementation of the Warp Transactional Filesystem." But that paper does not talk about the internals of Warp protocol like this archive report, rather talks about the Warp Transactional Filesystem (WTF), a transactional, POSIX-compatible filesystem built on top of Warp.
Design of the acyclic commit protocol
The acyclic transactions commit protocol processes clients' transactions, and ensures that they either commit in an atomic, serializable fashion, or abort with no effect.


Validation and ordering
The validation step ensures that values previously read by the client remain unchanged until the transaction commits. To do this, servers check each transaction to ensure that it does not read values written by, or write values read by, previously validated transactions. Servers also check each value against the latest value in their local store to ensure that the value was not changed by a previously-committed transaction. Thus, acyclic transactions employ optimistic concurrency control.
When a server determines that a transaction does not validate, the server aborts the transaction by sending an abort message backwards through the chain. Each server in the prefix aborts the transaction and forwards the abort message until the message reaches the client. These servers remove the transaction from their local state, enabling other transactions to validate in its place.

To ensure that all transactions commit in a serializable order across servers, servers embed ordering information, called mediator tokens, into transactions. Mediator tokens are integer values that are assigned to transactions by the heads of chains. A simple invariant that ensures serializability is to commit conflicting pairs in the order specified by their mediator tokens. For example, if the mediator tokens for the conflicting pair (TX , TY) have the relationship mediator(TX ) < mediator(TY), then all servers order the transactions such that TX commits before TY.
The acyclic transactions protocol relies on this invariant to order transactions. Upon receipt of a transaction passing forward through the chain, a server compares the transaction's mediator token to the largest mediator token across all transactions that previously read or wrote any of the current transaction's objects. If the current mediator token is larger than the previous token, the transaction is forwarded to the next server in the chain. If, however, the mediator token is less than the previous token, a *"retry"* message is sent backwards in the chain to the head, where the transaction will be retried with a larger mediator token.
To recap, an invalidated transaction is aborted and cleared by communicating backwards in the chain. But a still-valid transaction, whose serialization ordering does not work with the current mediator token number, is given another chance to serialize by being sent back to the head of the chain to take a new token number to retry. During the retry it may turn out that the readset for the transaction is not valid anymore with this ordering, and the transaction may end up aborting. Or the transaction may just work with this ordering without being invalidated.
There is an interesting parallel here with the CockroachDB commit protocol. CockroachDB commit uses 2PC OCC, but also performs timestamp-advancing and read-refreshing/validation. The difference is that, while those require more complicated operations and contacting more nodes in parallel in CockroachDB, the same process is handled elegantly and more efficiently (with little waste) in Warp.
"Certain types of conflicts described above require advancing the commit timestamp of a transaction. To maintain serializability, the read timestamp must be advanced to match the commit timestamp. Advancing a transaction’s read timestamp from ta to tb > ta is possible if we can prove that none of the data that the transaction read at ta has been updated in the interval (ta,tb]. If the data has changed, the transaction needs to be restarted. To determine whether the read timestamp can be advanced, CockroachDB maintains the set of keys in the transaction’s read set (up to a memory budget). A "read refresh" request validates that the keys have not been updated in a given timestamp interval (Algorithm 1, Lines 11 to 14). This involves re-scanning the read set and checking whether any MVCC values fall in the given interval."
By serializing/bottlenecking potentially conflicting transactions through chaining, Warp enforces handling/addressing of the conflicts earlier on and resolve them with little waste by either accepting them together with no serializability problems or aborting some of them. Retries are simple, and they make reordering easier. Moreover, invalidation happens earlier, with little wasted work, which also contributes to improved throughput. As such, Warp improves throughput.
Implementation and evaluation
They implemented Warp in 130,000 lines of code, approximately 15,000 lines of which are devoted to processing transactions. A system of virtual servers maps a small number of servers to a larger number of partitions, permitting the system to reassign partitions to servers without repartitioning the data. The implementation uses a replicated state machine as the coordinator to ensure that there are no single points of failure. The expanded API in the implementation includes support for rich data structures, multiple independent schemas, and nested transactions. (As far as I can see the implementation is not available as opensource.)
In the evaluation of the paper, they also compare Warp to HyperDex, the underlying NoSQL key-value store for Warp, even though HyperDex offers no transactional guarantees. For comparison purposes, they also implemented Sinfonia's mini-transactions on top of HyperDex, and refer to this implementation as MiniDex.


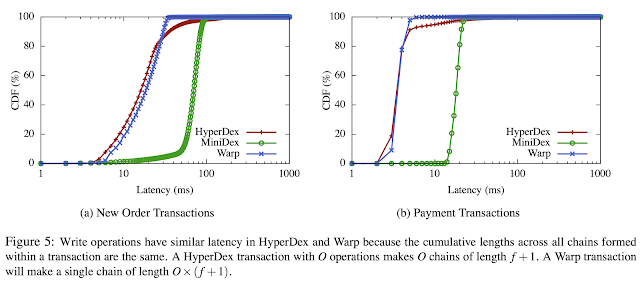

The experiments show that Warp achieves 4x higher throughput than
Sinfonia's mini-transactions on the standard TPC-C benchmark with no
aborts. Despite providing ACID guarantees, Warp also achieves 75% of the
throughput of the non-transactional key-value store it builds upon.
Aside from TPC-C workload, they also use targeted micro-benchmarks for experiments, where objects have 12 Byte keys and 64 Byte values, and are constructed uniformly at random. Ten million objects are preloaded onto the cluster before performing each benchmark.






Comments
While this is true, it’s generally not as expensive as it sounds. In particular, the underlying storage engine (pebble) provides an optimization called time-bound iteration whereby only SSTs in the LSM which contain write in the time interval being refreshed need to be searched. In the common case, this is just the memtable and so no io needs to be performed. Even when reading an sst is required, it usually experiences far less read amplification than a normal scan. Finally, the lsm iteration can also skip blocks using time bound iteration for further efficiency gains.