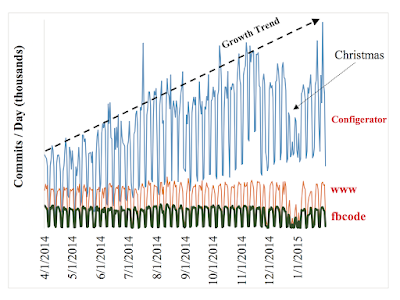
Paper review: Implementing Linearizability at Large Scale and Low Latency (SOSP'15)

Motivation for the paper Remember the 2-phase commit problem? The 2-phase commit blocks when the initiator crashes. Or, after a server crash the client/initiator may not be able to determine whether the transaction is completed. And transaction blocks. Because if we retry we may end up giving inconsistent result or redoing the transaction which messes up linearizability. You need to have 3-phase commit to fix this. The new-leader/recovery-agent comes and tries to recommit things. Unfortunately, 3-phase commit solutions are complicated, there are a lot of corner cases. Lamport and Gray recommended that the Paxos consensus box can be used to remember the initiator's abort commit decision to achieve consistency, or more precisely they recommended the Paxos box remembers each participants decision for the sake of shaving off a message in critical latency path. What this paper recommends is an alternative approach. Don't use Paxos box to remember the decision, instead use a